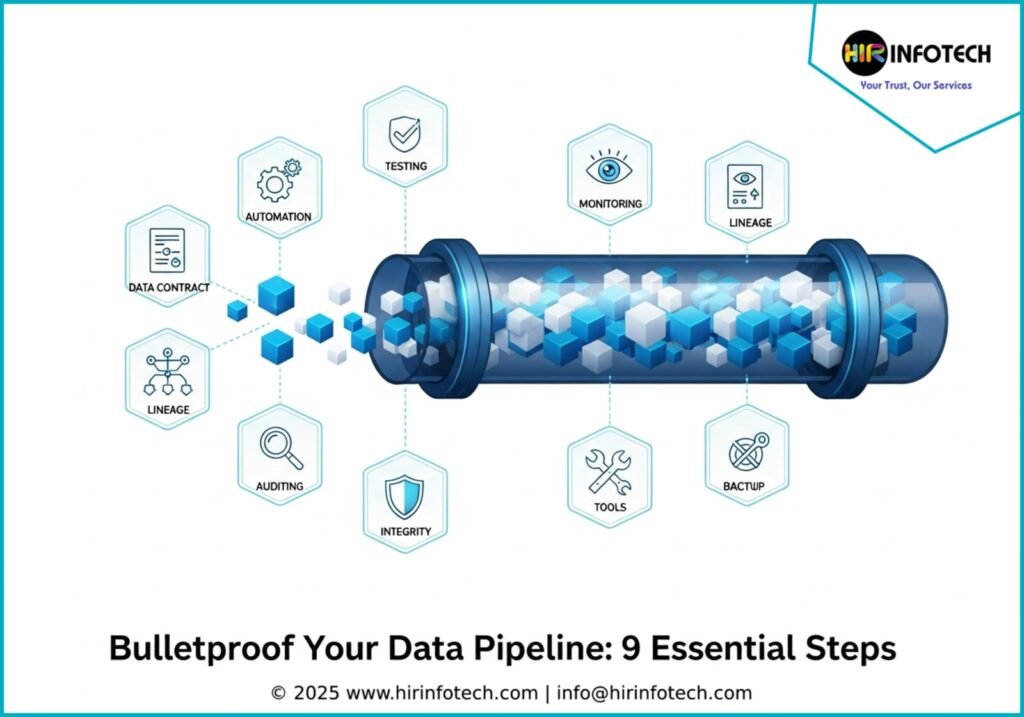
Tired of Faulty Data? Here’s How to Bulletproof Your Data Pipeline in 2026
In today’s data-driven world, your business operations rely on a steady, accurate flow of information. A data pipeline, the automated system that moves data from point A to point B, is the backbone of this process. But when this pipeline breaks, it can cause major disruptions, leading to flawed insights and poor business decisions. The good news is that you can prevent these costly errors.
This guide will walk you through the best practices for creating a resilient, error-free data pipeline, tailored for non-technical audiences at mid-to-large companies. We’ll cover everything from automated testing to investing in the right tools, ensuring your data remains a reliable asset for your entire organization.
What is a Data Pipeline and Why Does it Break?
Think of a data pipeline as an automated assembly line for your data. It extracts information from various sources (like your CRM, website analytics, or customer surveys), transforms it into a usable format, and delivers it to a destination, such as a data warehouse or a business intelligence tool.
However, just like a physical assembly line, a data pipeline can break down. Common causes of failure include:
- Changes at the Source: A simple modification, like renaming a column in a database, can bring your pipeline to a halt.
- Poor Data Quality: Incomplete or incorrectly formatted data entering the pipeline can cause significant issues downstream.
- Unexpected Data Volume: A sudden surge in data can overwhelm your system if it isn’t designed to scale.
- Network Issues: Unstable connections can interrupt data transfer, leading to incomplete information.
The impact of these failures can be severe, eroding trust in your data and leading to costly mistakes. Fortunately, with a proactive approach, you can build a robust data pipeline that withstands these challenges.
1. Embrace Automation with Proactive Testing
The first line of defense against a faulty data pipeline is automated testing. Instead of manually checking for errors, you can implement automated tests that constantly monitor your data for anomalies. These tests can identify sudden changes in data flow or inconsistencies in your datasets, allowing you to catch and fix potential problems before they escalate.
By integrating automated validation checks early in your pipeline, you can ensure that “garbage in, garbage out” is not a phrase that applies to your data. This proactive approach saves time and prevents poor-quality data from influencing critical business decisions. According to Gartner, poor data quality can cost companies an average of $15 million annually, making automated testing a crucial investment.
2. Monitor Your Data Sources Vigilantly
The sources of your data are often the most unpredictable part of your pipeline. It is vital to keep a close eye on them to ensure they are consistently providing accurate and complete information.
Consider a customer satisfaction survey as a data source. You need to ensure the survey is capturing all the necessary details, such as the respondent’s name and contact information, in a consistent format. Any unexpected changes or inconsistencies in the data from your sources should be addressed immediately to prevent them from corrupting your pipeline.
3. Prioritize Data Accuracy and Integrity
The data flowing through your pipeline informs company-wide decisions, so its accuracy is paramount. Your teams must be diligent in verifying the integrity of the data. This includes:
- Double-checking all data sources.
- Verifying that no data is missing or incorrect.
- Performing manual checks to confirm the information’s accuracy.
While manual checks are important, automated tools can significantly enhance your ability to manage data accuracy. These tools can detect and correct issues before they become problems, ensuring your data is always reliable. When choosing automation tools, look for solutions that are both dependable and easy for your team to use.
4. Develop a Robust Backup and Recovery Plan
No matter how well-prepared you are, errors can still happen. That’s why having a solid backup and recovery plan is essential. This strategy will enable you to recover from a data pipeline failure quickly and with minimal disruption to your business operations.
An effective backup plan requires that your team knows exactly what to do in an emergency. Regular training sessions can help keep everyone familiar with the company’s contingency plans and any new procedures. This preparedness will ensure a swift and organized response when an issue arises.
5. Invest in High-Quality Data Tools
To effectively monitor and maintain your data pipelines, you need the right tools. High-quality software, especially automation technologies like ETL (Extract, Transform, Load) tools, can help you quickly identify and fix problems before they disrupt your data flow. Many of these tools provide real-time feedback, ensuring your data is always accurate and up-to-date.
Investing time to research and select the right solutions will pay dividends in the long run. By choosing quality tools, you can ensure your data pipeline operates efficiently and reliably, preventing costly disruptions and empowering your teams with trustworthy data. For a look at some of the top tools available, check out this guide on Forbes Advisor.
6. Implement Comprehensive Logging and Auditing
Logging and auditing are fundamental practices for monitoring your data pipelines. Logging helps you quickly spot any errors or inconsistencies, while auditing ensures that your data is both reliable and secure.
It’s a good practice to review your logs regularly and investigate any irregularities immediately. Auditing tools can also help you verify that your data is secure and compliant with industry standards. By utilizing logging and auditing, your teams can rapidly find and address issues before they become critical problems.
7. Adopt Data Observability for Deeper Insights
In 2026, it’s not enough to just monitor your data pipelines; you need to understand the health of the data within them. This is where data observability comes in. Data observability provides an end-to-end understanding of your data’s health by monitoring, detecting, and resolving issues in real-time.
Unlike traditional monitoring, which only tells you if a system is up or down, data observability offers deep insights into your data’s quality, freshness, and lineage. This allows your teams to proactively identify and prevent problems, building greater trust in your data across the organization. Platforms like Datadog offer comprehensive observability solutions.
8. Establish Data Contracts to Ensure Consistency
A data contract is a formal agreement between the creators of data and the teams that use it. This agreement defines the expected structure, format, and quality of the data. By implementing data contracts, you can prevent unexpected changes at the source from breaking your downstream processes.
Think of it as a blueprint for your data. If a change is proposed that violates the contract, it’s flagged before it can cause a problem. This proactive approach to data governance is becoming essential for maintaining reliable data pipelines in complex business environments.
9. Understand Data Lineage to Trace Your Data’s Journey
Data lineage provides a complete map of your data’s journey, from its origin to its final destination. It shows you how data is transformed and used at every stage of the pipeline. This transparency is crucial for several reasons:
- Troubleshooting: When an error occurs, data lineage allows you to quickly trace it back to its root cause.
- Compliance: For regulations like GDPR, you need to know exactly how data is being used and processed.
- Impact Analysis: Before making changes to a data source, you can see all the downstream processes that will be affected.
By understanding the path your data takes, you gain greater control and can ensure its integrity throughout its lifecycle.
Build a Resilient Data Future with Hir Infotech
A reliable data pipeline is the foundation of a successful data-driven business. By implementing these best practices, you can build a resilient system that delivers accurate, timely, and trustworthy data. From automated testing and vigilant monitoring to investing in quality tools and embracing modern concepts like data observability and data contracts, you have the power to create an error-free data pipeline.
At Hir Infotech, we specialize in providing cutting-edge data solutions, including web scraping, data extraction, and comprehensive data management. Our experts can help you design and implement a robust data pipeline tailored to your company’s unique needs.
Ready to bulletproof your data pipeline? Contact Hir Infotech today to learn how our data solutions can empower your business to make smarter, data-driven decisions.
#DataPipeline #DataQuality #DataManagement #BusinessIntelligence #DataAnalytics #TechSolutions #BigData #Automation #ErrorFreeData #HirInfotech
Frequently Asked Questions (FAQs)
1. What are the key stages of a data pipeline?
A typical data pipeline consists of three main stages: data ingestion (extracting data from sources), data processing (transforming and cleaning the data), and data delivery (loading the data into a destination like a data warehouse).
2. What is the difference between ETL and ELT?
ETL (Extract, Transform, Load) and ELT (Extract, Load, Transform) are two approaches to data integration. In ETL, data is transformed before it’s loaded into the destination. In ELT, raw data is loaded first and then transformed within the destination system. ELT is often favored in modern, cloud-based data architectures for its flexibility and scalability.
3. How can I improve the scalability of my data pipeline?
To ensure your data pipeline can handle growing volumes of data, consider using cloud-based solutions that can scale resources up or down as needed. Designing your pipeline with a modular architecture also helps, as you can scale individual components independently.
4. What are some common open-source tools for building data pipelines?
There are several powerful open-source tools for data pipelines. Some popular choices include Apache Airflow for workflow orchestration, Apache Spark for large-scale data processing, and Kafka for real-time data streaming.
5. How does data governance relate to data pipelines?
Data governance provides the framework of rules and processes for managing your data assets. For data pipelines, this includes defining data ownership, establishing data quality standards, and ensuring compliance with regulations. Strong data governance is essential for maintaining a reliable and trustworthy data pipeline.
6. What is a “data mesh” and how does it impact data pipelines?
A data mesh is a decentralized approach to data architecture where data is treated as a product and managed by specific business domains. This can lead to more scalable and flexible data pipelines, as individual teams have more ownership and autonomy over their data.
7. How often should I review and update my data pipeline?
It’s a good practice to review your data pipeline’s performance and health regularly, at least on a quarterly basis. Additionally, any significant changes in your data sources, business requirements, or technology stack should trigger a review and potential update of your pipeline.


