
29-January-2026
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...
For over 13 years, Hir Infotech has empowered 2,745+ businesses across the USA, Europe, and Australia with precision-engineered, AI-driven web scraping services that deliver structured, decision-ready data at scale. As a globally recognized leader in AI-powered data extraction, automated web crawling, and data intelligence, we help B2B enterprises — from mid-market challengers to Fortune-listed organizations — eliminate manual data bottlenecks and gain a relentless competitive edge. Whether your team needs real-time price intelligence, lead enrichment, market research, or compliance-ready datasets, Hir Infotech delivers with unmatched accuracy, speed, and transparency.researchandmarkets+1

13+
Industry Experience
2,745+
Happy Clients
99.5%
Data Accuracy Rate
50M+
Records Extracted Monthly
120+
Industries Served
In 2026, AI-driven web scraping is no longer a niche technical capability — it is foundational data infrastructure for every competitive enterprise. The global AI-driven web scraping market is valued at USD 10.2 billion in 2026, projected to reach USD 23.7 billion by 2030 at a 23.5% CAGR, reflecting how urgently organizations across the USA, UK, Germany, France, Netherlands, Sweden, and Australia are racing to harness structured web data. For B2B companies, the ability to automatically extract, structure, and activate real-time external data — pricing signals, competitor movements, lead intelligence, regulatory filings, and market sentiment — translates directly into faster decisions, leaner operations, and measurable revenue growth.linkedin+1 Hir Infotech's AI-driven web scraping services are engineered specifically for mid-market and enterprise B2B organizations that require scale, compliance, and precision. With 13+ years of delivery experience and 2,745+ satisfied clients across the USA, Europe, and Australia, our team combines machine learning-powered crawlers, self-healing extraction pipelines, and human QA oversight to deliver data that is clean, structured, and integration-ready from day one.
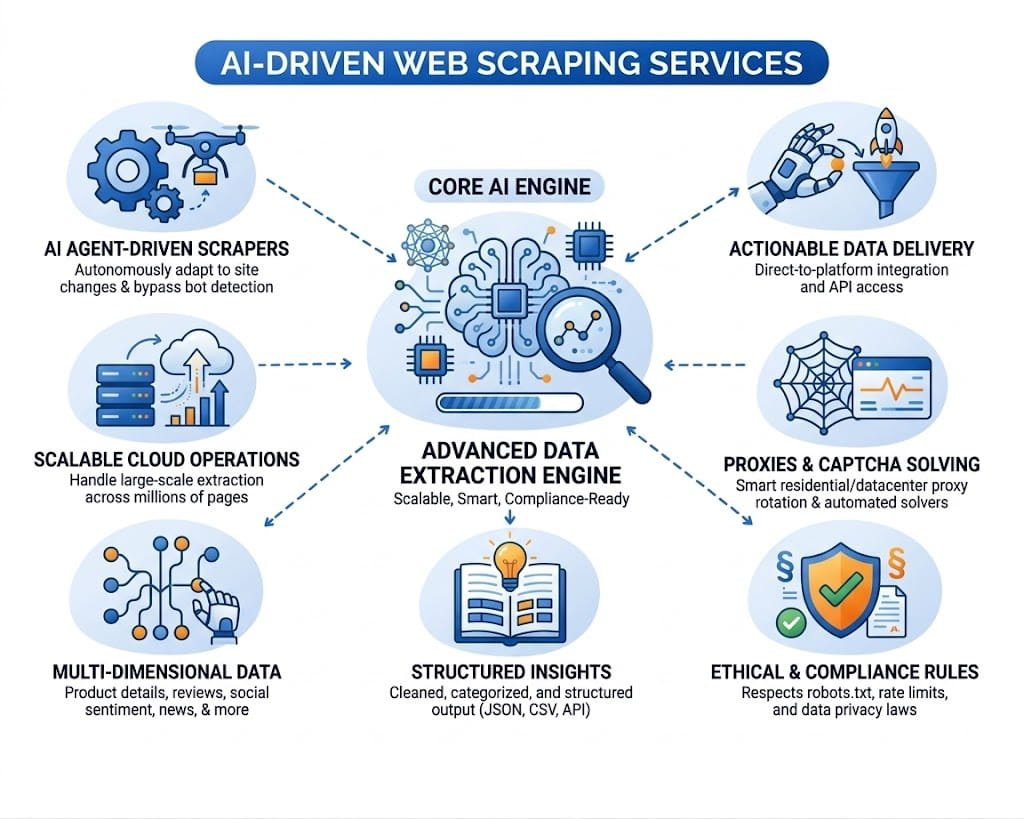
Our Core AI Web Scraping Service Capabilities:
Hir Infotech deploys a multi-layer AI scraping stack — combining LLM-assisted parsing, vision-based extraction, proxy rotation, and real-time QA — to deliver enterprise-grade web data with zero downtime and full compliance coverage.illusory+1
Our scrapers leverage large language model (LLM) reasoning to semantically understand web content — not just CSS selectors — enabling accurate extraction from unstructured pages, news articles, financial filings, and complex product catalogs without brittle rule-based scripts.
Our infrastructure incorporates enterprise-grade rotating residential and datacenter proxies, browser fingerprint management, CAPTCHA resolution, and rate-limiting controls — ensuring maximum success rates even against aggressive anti-scraping measures on protected enterprise platforms.
Using computer vision combined with text analysis, Hir Infotech extracts data from image-heavy pages, PDFs, and visually structured documents — capturing product images, scanned tables, and embedded data fields that traditional scrapers cannot access.
Whether you need a one-time bulk data harvest or continuous real-time monitoring with minute-level refresh intervals, Hir Infotech’s extraction orchestration platform supports both models — with alerting, scheduling, and delivery pipelines configurable to your exact operational cadence.
















Hir Infotech scrapes product prices, stock availability, promotions, and seller rankings from platforms like Amazon, eBay, and Zalando across the USA, UK, and Germany — enabling dynamic pricing strategies that keep B2B sellers 42% more competitive.apiscrapy+1
Extract verified company profiles, executive contacts, employee counts, and firmographic data from LinkedIn, Yellow Pages (USA), Kompass (Europe), and True Local (Australia) to build high-intent B2B sales pipelines at scale without manual prospecting.scraperapi+1
Monitor competitor product launches, pricing changes, PR announcements, and client acquisition signals across industry websites, press release aggregators, and news portals in the USA, UK, Netherlands, and Sweden — giving strategy teams a 24/7 competitive radar.
Aggregate real-time job postings, skill demand signals, salary benchmarks, and hiring velocity data from Indeed (USA/Global), Reed (UK), and StepStone (Germany/Europe) — enabling HR tech platforms and workforce analytics tools to power their products with live data.
Scrape earnings reports, SEC filings, regulatory announcements, interest rate data, and fund performance metrics from financial portals across the USA, EU, and Australia — delivering structured, audit-ready datasets to fintech platforms, investment firms, and risk analytics teams.
Extract property listings, price trends, rental yields, and market velocity data from Zillow (USA), Rightmove (UK), Immobilienscout24 (Germany), and Domain.com.au (Australia) — powering real estate analytics platforms and investment intelligence tools with comprehensive market coverage.
Collect physician directories, hospital listings, clinical trial registrations, drug approval data, and healthcare provider intelligence from CMS.gov (USA), NHS Digital (UK), and EMA (EU) — supporting health tech companies with structured, compliance-verified data pipelines.
Continuously extract hotel rates, flight prices, availability calendars, and review sentiment from Booking.com, Expedia, and Airbnb across Europe and the USA — enabling travel tech and OTA businesses to optimize pricing models with real-time market signals.
Aggregate structured product reviews, ratings, sentiment data, and consumer feedback from Trustpilot (Global), Google Reviews, Yelp (USA), and Trustindex (Europe) — delivering actionable voice-of-customer intelligence that drives product and marketing decisions.ssa+1
The volume of commercially valuable data publicly available on the web is growing at an unprecedented rate — yet most B2B organizations are still harvesting a fraction of it due to technical limitations, compliance uncertainty, and resource constraints. AI-driven web scraping solves all three simultaneously. Organizations implementing AI-powered extraction pipelines outperform competitors by 47% on competitive intelligence velocity and generate up to $167,000 more in annual value per implementation site by eliminating data latency from their decision cycles. Hir Infotech’s managed AI scraping service removes every barrier to entry: we design, deploy, monitor, and maintain your extraction infrastructure end-to-end, delivering clean, structured datasets on your schedule — so your data, product, and strategy teams can focus entirely on extracting value, not fixing broken scrapers.linkedin+1
For enterprises operating across multiple markets — particularly in the USA, UK, Germany, France, Italy, Spain, Denmark, Netherlands, Iceland, Austria, Sweden, Switzerland, and Australia — Hir Infotech provides geo-targeted extraction with regional compliance controls built in. Our workflows respect robots.txt protocols, apply jurisdiction-specific PII filters, maintain request-level audit logs, and align with GDPR, CCPA, and the EU AI Act’s data governance requirements, making us the trusted AI web scraping partner for regulated industries including fintech, healthcare, insurance, and retail.xbyte+1
Raw scraped data has no value until it is structured, validated, enriched, and delivered in a format your systems can act on immediately. This is the gap that separates Hir Infotech from generic data brokers and offshore freelancers. Our end-to-end AI data intelligence layer — applied after every extraction — includes entity resolution, deduplication, schema normalization, sentiment tagging, and anomaly flagging, so what arrives in your data warehouse or CRM is decision-grade intelligence, not messy HTML dumps.kadoa+1
For B2B product leaders, CTOs, and CDOs across the USA and Europe, this means faster onboarding of external data sources into existing analytics stacks, BI platforms (Tableau, Power BI, Looker), and CRM systems (Salesforce, HubSpot) without costly internal data engineering. Our clients in industries including e-commerce, SaaS, financial services, healthcare, logistics, real estate, and market research consistently report 60–80% reductions in time-to-insight after migrating to Hir Infotech’s managed AI scraping and data intelligence service. With 2,745+ happy clients and 13+ years of hands-on delivery expertise, we have the proven playbook to deploy structured, scalable, compliant data pipelines for your specific use case — in weeks, not months.retailscrape+1
Client Background
A mid-market B2B retail technology platform based in Chicago, Illinois, providing dynamic pricing software to over 200 U.S. retail brands, needed a reliable, scalable source of competitor price data across 15 major e-commerce marketplaces.
Challenge
The client’s internal scraping infrastructure was fragile, frequently breaking due to website layout changes, and the engineering team was spending 30+ hours per week maintaining scrapers instead of building product features. Data freshness was averaging 48–72 hours behind market conditions — a critical lag in a market where pricing changes hourly.
Solution
Hir Infotech replaced the client’s in-house scraper stack with a fully managed AI extraction pipeline covering Amazon, Walmart, Target, eBay, and 11 additional marketplaces. Our self-healing AI agents monitor each source 24/7, automatically adapting to layout and schema changes. Data is delivered via API in real-time, with price change alerts triggered within 15 minutes of detection.
Results
Client Testimonial
“Hir Infotech didn’t just fix our data pipeline — they transformed it into a genuine competitive weapon for our customers. The accuracy, the speed, and the zero-maintenance promise are all real. We haven’t touched a scraper config in seven months.”
— VP of Product, Retail Technology Platform, Chicago, USA
Client Background
A fast-growing B2B SaaS company headquartered in London with operations expanding into Germany, France, and the Netherlands needed a high-volume, verified lead database of mid-market manufacturing and logistics companies across Western Europe.
Challenge
The client’s sales development team was manually sourcing leads from LinkedIn, Kompass, and industry directories — a process yielding only 400–600 new contacts per month at unacceptably high cost per lead. Existing data providers delivered stale records with 30–40% bounce rates.
Solution
Hir Infotech deployed a custom AI-powered lead extraction pipeline targeting 12 European business directories, trade association member portals, and company registry databases in the UK, Germany, France, and the Netherlands. Our NLP enrichment layer cross-referenced company profiles with news feeds and LinkedIn signals to score leads by intent and recency.
Results
Client Testimonial
“The quality leap was immediate. Our SDRs went from drowning in bad data to having a curated, scored pipeline every Monday morning. Hir Infotech’s team understood our market deeply and delivered exactly what we needed — without us having to chase them once.”
— Head of Sales Development, B2B SaaS Company, London, UK
Client Background
A Frankfurt-based financial intelligence firm providing institutional clients across the EU with structured market research data, economic indicators, and regulatory tracking required automated extraction from 200+ financial and government data sources across 15 European markets.
Challenge
Manual data collection was creating a 5–7 day lag in research publication timelines. The firm’s analysts were spending 60% of their time on data gathering rather than analysis. Additionally, GDPR and EU AI Act compliance requirements for data provenance were creating governance risks with their existing unmanaged scraping approach.
Solution
Hir Infotech built a fully compliant AI-driven data intelligence pipeline covering ECB publications, national central bank portals, Eurostat, regulatory filing databases, and 190+ financial news sources across Germany, France, Italy, Spain, Austria, Switzerland, and the Netherlands. Every data point is logged with source URL, extraction timestamp, and jurisdiction tag for complete audit trail compliance.
Results
Client Testimonial
“Our institutional clients demand data that is both current and completely audit-ready. Hir Infotech understood our compliance environment from day one and built a pipeline that our legal team, not just our data team, could fully stand behind.”
— Chief Data Officer, Financial Intelligence Firm, Frankfurt, Germany
Client Background
A Sydney-based property technology company building an AI-powered real estate investment analytics platform for Australian and APAC institutional investors required structured, real-time property listing and market data from across Australia’s fragmented property portals.
Challenge
Australia’s real estate data landscape is highly fragmented across Domain, REA Group, state government land registries, and hundreds of local agency portals. The client had attempted to build internal scrapers twice, both abandoned due to maintenance overhead and bot detection failures.
Solution
Hir Infotech deployed a multi-source AI extraction network covering Domain.com.au, realestate.com.au, CoreLogic-adjacent public data portals, and 80+ regional agency websites. Our vision-based extraction engine handled image-heavy listing pages, while our NLP layer standardized property attributes across inconsistent schemas. Data is delivered via real-time API with suburb-level segmentation.
Results
Client Testimonial
“We’d burned two engineering quarters trying to solve this ourselves. Hir Infotech solved it in six weeks and built something more reliable than anything we could have built internally. Their knowledge of the Australian property data landscape was genuinely impressive.”
— CTO, PropTech Platform, Sydney, Australia
Client Background
A Boston-based healthcare technology company serving hospital systems across the USA and four EU markets needed continuous competitive monitoring across 50+ competitor websites, clinical trial registries, FDA and EMA filings, and healthcare trade media.
Challenge
The company’s market intelligence function was under-resourced — one analyst manually reviewing 50+ sources three times per week, missing critical competitive signals and regulatory filings that were influencing procurement decisions at target hospital systems.
Solution
Hir Infotech designed an AI-powered competitive intelligence data pipeline covering FDA.gov, EMA.europa.eu, ClinicalTrials.gov, competitor investor relations pages, and 30 healthcare trade publications. Our sentiment analysis layer flagged competitive risk signals — new product approvals, pricing changes, partnership announcements — and delivered structured alerts to the client’s Slack and CRM integrations within 2 hours of publication.
Results
Client Testimonial
“We were flying blind relative to our competitors. Hir Infotech gave us a structured, reliable intelligence feed that our sales and strategy teams now treat as essential infrastructure. The ROI was visible within the first 60 days.”
— Chief Marketing Officer, Healthcare Technology Company, Boston, USA
Client Background
A Stockholm-based online travel aggregator operating across Sweden, Denmark, Norway, Iceland, and Finland required real-time hotel rate, availability, and promotion data from 12 major travel platforms and 800+ independent hotel websites across the Nordic region.
Challenge
The client’s existing rate monitoring solution covered only major OTAs and missed 40% of the Nordic market — primarily independent and boutique hotel inventory. Their pricing optimization models were consequently underperforming, costing an estimated SEK 8M annually in suboptimal booking conversion.
Solution
Hir Infotech built a comprehensive Nordic travel rate intelligence pipeline combining major OTA scraping (Booking.com, Expedia, Hotels.com) with targeted extraction from 800+ independent hotel and regional tourism portal websites across Sweden, Denmark, Norway, Iceland, and Finland. Real-time availability data is delivered every 15 minutes via REST API into the client’s pricing optimization engine.
Results
Client Testimonial
“Hir Infotech gave us genuine market coverage for the first time. The depth of their Nordic travel data, including the independent hotels that no one else was capturing, completely changed the performance of our pricing engine.”
— Head of Data & Pricing, OTA Platform, Stockholm, Sweden
Client Background
A mid-market B2B retail technology platform based in Chicago, Illinois, providing dynamic pricing software to over 200 U.S. retail brands, needed a reliable, scalable source of competitor price data across 15 major e-commerce marketplaces.
Challenge
The client’s internal scraping infrastructure was fragile, frequently breaking due to website layout changes, and the engineering team was spending 30+ hours per week maintaining scrapers instead of building product features. Data freshness was averaging 48–72 hours behind market conditions — a critical lag in a market where pricing changes hourly.
Solution
Hir Infotech replaced the client’s in-house scraper stack with a fully managed AI extraction pipeline covering Amazon, Walmart, Target, eBay, and 11 additional marketplaces. Our self-healing AI agents monitor each source 24/7, automatically adapting to layout and schema changes. Data is delivered via API in real-time, with price change alerts triggered within 15 minutes of detection.
Results
Client Testimonial
“Hir Infotech didn’t just fix our data pipeline — they transformed it into a genuine competitive weapon for our customers. The accuracy, the speed, and the zero-maintenance promise are all real. We haven’t touched a scraper config in seven months.”
— VP of Product, Retail Technology Platform, Chicago, USA
Client Background
A fast-growing B2B SaaS company headquartered in London with operations expanding into Germany, France, and the Netherlands needed a high-volume, verified lead database of mid-market manufacturing and logistics companies across Western Europe.
Challenge
The client’s sales development team was manually sourcing leads from LinkedIn, Kompass, and industry directories — a process yielding only 400–600 new contacts per month at unacceptably high cost per lead. Existing data providers delivered stale records with 30–40% bounce rates.
Solution
Hir Infotech deployed a custom AI-powered lead extraction pipeline targeting 12 European business directories, trade association member portals, and company registry databases in the UK, Germany, France, and the Netherlands. Our NLP enrichment layer cross-referenced company profiles with news feeds and LinkedIn signals to score leads by intent and recency.
Results
Client Testimonial
“The quality leap was immediate. Our SDRs went from drowning in bad data to having a curated, scored pipeline every Monday morning. Hir Infotech’s team understood our market deeply and delivered exactly what we needed — without us having to chase them once.”
— Head of Sales Development, B2B SaaS Company, London, UK
Client Background
A Frankfurt-based financial intelligence firm providing institutional clients across the EU with structured market research data, economic indicators, and regulatory tracking required automated extraction from 200+ financial and government data sources across 15 European markets.
Challenge
Manual data collection was creating a 5–7 day lag in research publication timelines. The firm’s analysts were spending 60% of their time on data gathering rather than analysis. Additionally, GDPR and EU AI Act compliance requirements for data provenance were creating governance risks with their existing unmanaged scraping approach.
Solution
Hir Infotech built a fully compliant AI-driven data intelligence pipeline covering ECB publications, national central bank portals, Eurostat, regulatory filing databases, and 190+ financial news sources across Germany, France, Italy, Spain, Austria, Switzerland, and the Netherlands. Every data point is logged with source URL, extraction timestamp, and jurisdiction tag for complete audit trail compliance.
Results
Client Testimonial
“Our institutional clients demand data that is both current and completely audit-ready. Hir Infotech understood our compliance environment from day one and built a pipeline that our legal team, not just our data team, could fully stand behind.”
— Chief Data Officer, Financial Intelligence Firm, Frankfurt, Germany
Client Background
A Sydney-based property technology company building an AI-powered real estate investment analytics platform for Australian and APAC institutional investors required structured, real-time property listing and market data from across Australia’s fragmented property portals.
Challenge
Australia’s real estate data landscape is highly fragmented across Domain, REA Group, state government land registries, and hundreds of local agency portals. The client had attempted to build internal scrapers twice, both abandoned due to maintenance overhead and bot detection failures.
Solution
Hir Infotech deployed a multi-source AI extraction network covering Domain.com.au, realestate.com.au, CoreLogic-adjacent public data portals, and 80+ regional agency websites. Our vision-based extraction engine handled image-heavy listing pages, while our NLP layer standardized property attributes across inconsistent schemas. Data is delivered via real-time API with suburb-level segmentation.
Results
Client Testimonial
“We’d burned two engineering quarters trying to solve this ourselves. Hir Infotech solved it in six weeks and built something more reliable than anything we could have built internally. Their knowledge of the Australian property data landscape was genuinely impressive.”
— CTO, PropTech Platform, Sydney, Australia
Client Background
A Boston-based healthcare technology company serving hospital systems across the USA and four EU markets needed continuous competitive monitoring across 50+ competitor websites, clinical trial registries, FDA and EMA filings, and healthcare trade media.
Challenge
The company’s market intelligence function was under-resourced — one analyst manually reviewing 50+ sources three times per week, missing critical competitive signals and regulatory filings that were influencing procurement decisions at target hospital systems.
Solution
Hir Infotech designed an AI-powered competitive intelligence data pipeline covering FDA.gov, EMA.europa.eu, ClinicalTrials.gov, competitor investor relations pages, and 30 healthcare trade publications. Our sentiment analysis layer flagged competitive risk signals — new product approvals, pricing changes, partnership announcements — and delivered structured alerts to the client’s Slack and CRM integrations within 2 hours of publication.
Results
Client Testimonial
“We were flying blind relative to our competitors. Hir Infotech gave us a structured, reliable intelligence feed that our sales and strategy teams now treat as essential infrastructure. The ROI was visible within the first 60 days.”
— Chief Marketing Officer, Healthcare Technology Company, Boston, USA
Client Background
A Stockholm-based online travel aggregator operating across Sweden, Denmark, Norway, Iceland, and Finland required real-time hotel rate, availability, and promotion data from 12 major travel platforms and 800+ independent hotel websites across the Nordic region.
Challenge
The client’s existing rate monitoring solution covered only major OTAs and missed 40% of the Nordic market — primarily independent and boutique hotel inventory. Their pricing optimization models were consequently underperforming, costing an estimated SEK 8M annually in suboptimal booking conversion.
Solution
Hir Infotech built a comprehensive Nordic travel rate intelligence pipeline combining major OTA scraping (Booking.com, Expedia, Hotels.com) with targeted extraction from 800+ independent hotel and regional tourism portal websites across Sweden, Denmark, Norway, Iceland, and Finland. Real-time availability data is delivered every 15 minutes via REST API into the client’s pricing optimization engine.
Results
Client Testimonial
“Hir Infotech gave us genuine market coverage for the first time. The depth of their Nordic travel data, including the independent hotels that no one else was capturing, completely changed the performance of our pricing engine.”
— Head of Data & Pricing, OTA Platform, Stockholm, Sweden
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
With 12+ years of expertise, Hir Infotech has served 2745+ clients globally. Our proven scraping solutions drive B2B success across the USA, Europe, and Australia.
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...

Gain a powerful edge in the 2026 auto market. Leverage automotive data scraping to master dynamic pricing, analyze competitor strategies,...

Unlock smarter investment decisions using real-time LinkedIn data on company growth, talent, and leadership. Gain a critical competitive edge and...

Gain a competitive edge with a powerful News API. This guide explains how it automates data extraction, providing real-time insights...

Unlock powerful aviation intelligence for your travel business. Our 2026 guide to flight data scraping reveals how to track competitor...

Instantly build a powerful recruitment platform by web scraping job boards for thousands of fresh listings. Attract top talent and...
Stop guessing. Start knowing. With Hir Infotech’s AI-driven web scraping services, your team gets accurate, structured, compliance-ready data — delivered exactly when and how you need it.
Trusted by 2,745+ businesses across the USA, Europe, and Australia. 13+ years of AI data extraction expertise. 99.5% accuracy rate. 100% GDPR & CCPA compliant.
Whether you need competitive intelligence, lead data, price monitoring, or market research — we’ll prove our quality before you commit. Request a free data sample today and experience enterprise-grade AI extraction firsthand.
Your competitors are already using AI to extract market intelligence at scale. Hir Infotech gives you the same capability — managed, compliant, and production-ready in weeks. Let’s build your data advantage together.researchandmarkets+1
Hir Infotech’s AI extraction pipelines deliver 99.5% data accuracy across millions of records per month — eliminating the data quality errors that corrupt analytics models, inflate CRM churn, and derail pricing decisions at enterprise B2B organizations.
Extracted data is delivered in your required format — JSON, CSV, XML, REST API, webhooks — with native compatibility for Salesforce, HubSpot, Tableau, Power BI, Snowflake, BigQuery, and custom data warehouses, eliminating integration friction.
Hir Infotech extracts data from sources across the USA, UK, Germany, France, Italy, Spain, Denmark, Netherlands, Iceland, Austria, Sweden, Switzerland, and Australia — with regional compliance controls, language support, and local source knowledge built into every engagement.
Our AI agents automatically detect and adapt to website changes, anti-bot measures, and schema updates without human intervention — ensuring your data flows continue uninterrupted 24/7, with no engineering overhead for your internal team.
Whether you need 10,000 or 100 million records monthly, Hir Infotech’s cloud-native extraction infrastructure scales elastically with your demand — with no performance degradation, no infrastructure procurement delays, and pricing that scales proportionally.
Every extraction workflow includes lawful-basis documentation, PII exclusion controls, jurisdiction tagging, and audit-ready logs — protecting your organization from GDPR fines that have already surpassed €5.88 billion cumulatively and EU AI Act penalties effective August 2026.
Access live competitive pricing, product launch, and market signal data with sub-hour latency — enabling B2B strategy, sales, and product teams to respond to market changes in real time rather than working from week-old snapshots.
Hir Infotech’s proven delivery methodology launches production-grade data pipelines in 2–4 weeks — dramatically faster than in-house build timelines, which average 6–12 months and frequently overrun budget and scope.
Building and maintaining an enterprise AI scraping stack internally costs $250,000–$500,000+ annually in engineering salaries, infrastructure, and maintenance. Hir Infotech’s managed service delivers equivalent capability at a fraction of the cost, with guaranteed SLAs.
Every enterprise client receives a dedicated account manager, monthly performance reporting, source coverage audits, and SLA-backed delivery guarantees — providing the governance and transparency that procurement, legal, and CDO teams at mid-market and enterprise organizations require.
At Hir Infotech, we offer flexible pricing models to power your data-driven success. Choose Subscription-Based Pricing for ongoing scraping needs with predictable costs, Pay-As-You-Go for one-off tasks billed by usage, Project-Based Flat Fees for tailored, end-to-end solutions, or Hourly Pricing for custom development and complex challenges. Whatever your budget or project scope, our expert team delivers cost-effective, high-quality web scraping solutions designed to fit your needs.

A one-time fee is charged for a specific project, regardless of volume or duration, based on scope and complexity.
Billed based on the time spent developing, running, or maintaining the scraper, often used for custom or consulting-heavy projects.

Charged based on actual usage, such as per request, per GB of bandwidth, or per page scraped, with no fixed commitment.
pay a recurring fee (monthly or annually) for access to scraping services, often tiered based on usage limits like the number of requests, pages scraped, or data points extracted.
We begin by collaborating with you to define your data needs—be it for a one-time project, recurring insights, or custom solutions. Whether you opt for Pay-As-You-Go flexibility, a Project-Based Flat Fee, Hourly expertise, or a Subscription plan, we align our approach to your objectives.
Our team identifies the websites and data sources critical to your project. We analyze site structures, assess complexity (e.g., static vs. dynamic content), and plan the most efficient scraping strategy, ensuring compliance with public data access norms.
Using cutting-edge tools and custom-built scrapers, we extract data at scale. We tackle challenges like JavaScript-rendered pages or anti-scraping measures with techniques such as:
Raw data is parsed, cleaned, and structured into formats like CSV, JSON, or Excel. We remove duplicates, correct errors, and validate accuracy to ensure you receive reliable, ready-to-use datasets.
Depending on your pricing model, we deliver results how and when you need them:
We monitor site changes, adapt scrapers as needed, and provide support to keep your data flowing seamlessly. Subscription clients enjoy continuous updates, while Hourly clients benefit from hands-on refinements.
AI-driven web scraping uses machine learning, natural language processing, and computer vision to extract, understand, and structure data from web sources — intelligently adapting to layout changes and complex page structures without hardcoded rules. Traditional scrapers rely on brittle CSS selectors and XPath rules that break whenever a site updates. AI-driven extraction is self-healing, semantically aware, and capable of processing unstructured content (including PDFs, image-heavy pages, and JavaScript-rendered applications) that rule-based scrapers cannot handle. This makes AI-driven scraping the standard choice for enterprise B2B deployments requiring reliability and scale.retailscrape+1
Web scraping of publicly accessible data is broadly permitted under U.S. case law — including the landmark hiQ v. LinkedIn ruling — provided it does not circumvent authentication systems or violate the Computer Fraud and Abuse Act. In Europe, GDPR requires a lawful basis when scraping personal data, and the EU AI Act (enforcement beginning August 2026) adds data governance and transparency requirements for AI systems trained on scraped data. Hir Infotech operates a compliance-first extraction model, incorporating lawful-basis documentation, PII exclusion, robots.txt adherence, and jurisdiction-specific controls — ensuring your data acquisition is legally defensible across all major markets.tendem+1
Hir Infotech applies a multi-stage quality assurance process to every extraction pipeline: AI-powered validation at extraction (schema conformance, anomaly detection), cross-source reconciliation for high-value datasets, and human QA review for critical fields. Our pipelines are monitored 24/7 for drift, source changes, and data quality degradation, with automated alerts triggering review workflows. Clients consistently achieve 99.5%+ accuracy rates. For B2B use cases where data quality directly impacts revenue — such as lead generation, pricing intelligence, and financial research — this QA rigor is non-negotiable and is contractually backed by our SLAs.
For standard B2B use cases (lead generation, price monitoring, competitor intelligence, directory extraction), Hir Infotech delivers a production-ready extraction pipeline within 2–4 weeks of project kick-off, including source mapping, extraction development, QA validation, and delivery integration. Complex multi-source, multi-geography pipelines with custom enrichment and compliance controls typically require 4–8 weeks. This compares favorably to the 6–12 month in-house build timelines typical for enterprise teams, and we offer a free sample extraction before contract commitment, allowing you to verify quality and format fit at zero risk.
Hir Infotech delivers extracted data in all standard enterprise formats — CSV, JSON, XML, XLSX — and via REST API endpoints, SFTP scheduled transfers, webhook event streams, and direct database writes (PostgreSQL, MySQL, MongoDB, Snowflake, BigQuery). Data can be pre-structured to your exact schema, reducing or eliminating transformation work on your end. We support one-time bulk deliveries, scheduled batch jobs (hourly, daily, weekly), and real-time continuous streaming — with delivery method and cadence determined entirely by your operational requirements.
Yes. Hir Infotech’s AI extraction stack is built to handle the full spectrum of web complexity — including single-page applications (React, Angular, Vue.js), JavaScript-rendered content, infinite scroll pages, multi-step form navigation, and authenticated portals where data access is provided through legitimate API credentials or partner agreements. Our anti-bot bypass infrastructure, headless browser rendering, and residential proxy networks ensure high success rates even on aggressively protected platforms. Every source is individually assessed for technical complexity and compliance risk before inclusion in a client pipeline.forage+1
For all extraction work involving EU-based web sources, Hir Infotech applies GDPR-compliant protocols by design: we identify and exclude personal data categories (names, emails, phone numbers) unless a documented lawful basis exists; we maintain complete extraction logs with source URLs, timestamps, and jurisdiction tags; and we apply purpose-limitation controls that restrict data use to the stated business objective. Our compliance framework is aligned with GDPR Articles 6, 9, and 13 requirements, and we support clients in conducting Data Protection Impact Assessments (DPIAs) for high-volume extraction projects involving EU-resident data.xbyte+1
Hir Infotech delivers AI-driven web scraping and data intelligence services across 120+ industries, including: e-commerce and retail, financial services and fintech, healthcare and pharmaceuticals, real estate and proptech, travel and hospitality, SaaS and technology, logistics and supply chain, insurance, market research, media and publishing, legal intelligence, and government/public sector data. Our team has deep domain expertise in each vertical, enabling us to design source selection strategies, schema standards, and enrichment layers that are contextually relevant to your specific use case rather than generic data dumps.researchandmarkets+1
Generic data brokers sell pre-packaged, static datasets that are often outdated, unverified, and built for average use cases — not your specific schema, refresh cadence, or compliance requirements. Freelance scrapers offer low upfront costs but no SLAs, no QA, no compliance coverage, and no scalability. Hir Infotech is a fully managed, enterprise-grade AI web scraping partner: we custom-build your extraction pipeline to your exact specifications, maintain it indefinitely with 24/7 monitoring, guarantee accuracy and delivery SLAs, and provide full legal and compliance documentation. With 13+ years of experience and 2,745+ clients, we have the institutional knowledge, tooling, and infrastructure that neither brokers nor freelancers can replicate.
A typical enterprise engagement begins with a free sample extraction to validate source feasibility and data quality fit. Following kick-off, our team completes source mapping, pipeline development, compliance review, and QA validation within 2–4 weeks. Ongoing managed delivery is governed by a monthly SLA covering accuracy rate, uptime, and freshness. In terms of ROI, Hir Infotech clients commonly report: 60–80% reduction in analyst time spent on data gathering; 30–50% improvement in sales pipeline quality from AI-enriched lead data; and competitive intelligence latency reduced from days to hours. Organizations implementing AI-driven extraction consistently generate $167,000+ in additional annual value per use case versus manual alternatives.retailscrape+1
+91 99099 90610
+91 94096 28528
inquiry@hirinfotech.com