
29-January-2026
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...
In today’s hyper-competitive financial landscape, access to accurate, real-time credit data is no longer a luxury — it is a strategic necessity. Hir Infotech delivers enterprise-grade AI-driven credit data scraping, extraction, and intelligence solutions trusted by B2B decision-makers across the USA, Europe, and Australia. With 13+ years of specialized experience, 2,745+ satisfied clients, and proven delivery for mid-market and enterprise financial services firms, we transform publicly available credit data, alternative financial signals, and bureau-adjacent sources into structured, compliance-ready datasets — engineered to fuel smarter underwriting, risk modeling, and business growth.


500M+
Credit Sources Covered
99.2%
Data Accuracy Rate
2,745+
Happy Clients
13+
Years of Expertise
40+
Countries Served
The modern credit economy runs on data — but not just the data sitting inside a bureau. Lenders, fintechs, insurance providers, and B2B platforms across the USA, UK, Germany, France, the Netherlands, Sweden, Switzerland, and Australia are increasingly relying on AI-driven credit data scraping to enrich their risk models with alternative signals: business registry filings, payment histories from public platforms, court records, trade credit reports, and real-time financial news. According to industry research, 62% of financial institutions now use alternative data to improve credit risk profiling, creating an urgent need for scalable, compliant, and structured credit data extraction services. Hir Infotech bridges that gap — delivering enterprise-quality credit data pipelines built on 13+ years of experience and serving 2,745+ clients globally.
Hir Infotech deploys intelligent, multi-layered scraping infrastructure to extract, normalize, and deliver structured credit data at enterprise scale — covering lenders, fintechs, and risk platforms globally.
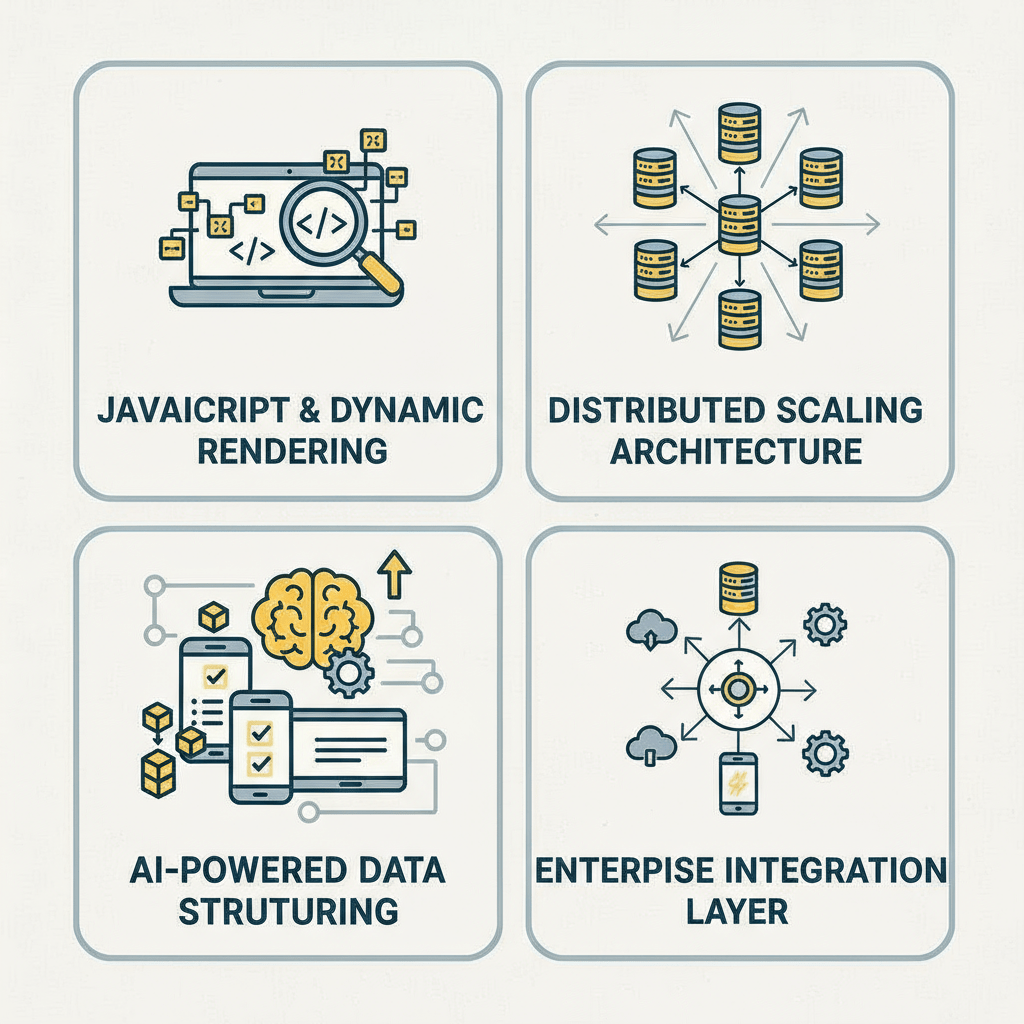
Our AI-powered OCR and NLP pipelines extract credit-relevant data from PDFs, regulatory filings, and semi-structured financial documents — converting unstructured bureau reports and public records into clean, machine-readable datasets.
Raw credit data from 500+ heterogeneous sources — bureaus, registries, news APIs, and fintech platforms — is normalized, deduplicated, and schema-mapped into consistent, CRM- and model-ready output formats (JSON, CSV, XML, database push).
Using enterprise-grade headless browser technology and rotating proxy infrastructure, Hir Infotech navigates JavaScript-heavy credit portals, lender directories, and financial registries — maintaining extraction continuity without detection or interruption.
Every credit data extraction workflow includes built-in GDPR Legitimate Interest Assessments, CCPA disclosure frameworks, DPIA documentation, and automated data purging schedules — ensuring enterprise clients pass regulatory audits with zero friction.
















Lenders and fintech platforms extract structured tradeline data, credit scores, and delinquency flags from public-facing credit bureau portals and consumer reporting directories in the USA (Experian, Equifax adjacent public data) and UK, enabling faster automated underwriting without manual data entry.
Companies Houseuk, Handelsregister (Germany), Chambre de Commerce (France), KvK (Netherlands), and Bolagsverket (Sweden) publish public business financial data — Hir Infotech extracts registration status, filed accounts, director details, and charge registers for B2B credit risk scoring.
Public court databases in the USA (PACER, state courts) publish judgment and lien data. Hir Infotech extracts CCJ-equivalent records, tax liens, and bankruptcies at scale — enabling collections teams and risk analysts to identify high-risk borrowers before underwriting.
Product leaders at financial institutions monitor platforms like LendingClub, Funding Circle, and Kabbage for interest rate benchmarks, loan product structures, and origination volume trends — scraped by Hir Infotech for competitive credit market intelligence.
Yelp (USA), Trustpilot (Global), and Google Business Reviews are scraped to extract business reputation signals — payment reliability indicators, owner responsiveness, and operational stability cues — enriching SME credit profiles beyond traditional bureau data.
Hir Infotech automates extraction of 10-K, 10-Q, 8-K, and EDGAR filings from SEC.gov, delivering structured financial metrics — debt ratios, covenant breaches, cash flow indicators — to institutional credit teams and corporate bond analysts.
B2B trade credit platforms such as Creditsafe and Dun & Bradstreet adjacent public data portals publish supplier payment performance data. Hir Infotech extracts Days Sales Outstanding (DSO), late payment trends, and credit limit changes for trade finance and procurement teams.
Public land registries and mortgage data portals in Australia (ASIC, state land titles) and the USA (FHFA, Freddie Mac databases) publish property ownership, mortgage origination, and default signal data — scraped and structured for REIT analysts and mortgage servicers.
Financial news portals — Reuters, Bloomberg public feeds, FT, and regional European financial press — are scraped for macroeconomic signals, central bank policy changes, and sector-level credit events that feed real-time risk models for hedge funds and asset managers.
The traditional bureau-only credit model is rapidly losing its edge. Across the USA, UK, Germany, the Netherlands, and Australia, forward-thinking lenders and credit risk platforms are augmenting bureau data with AI-scraped alternative credit signals — and the business impact is significant. By incorporating scraped data from business registries, payment platforms, court records, and news sources, lenders can assess borrowers who fall outside conventional credit history windows — including new immigrants, early-stage businesses, gig workers, and SMEs with thin bureau files. Hir Infotech’s AI-driven credit data scraping service delivers 99.2% extraction accuracy across 500+ sources, with structured output ready for immediate ingestion into ML-based credit scoring models, origination platforms, and risk dashboards. Our pipelines are optimized for high-volume, low-latency delivery — enabling same-day enrichment of loan applications at scale without engineering overhead on your side.
Regulatory risk is the single biggest barrier preventing financial institutions from scaling alternative data programs — and it is where most generic data providers fall short. Hir Infotech is purpose-built for regulated industries. Every credit data extraction engagement includes GDPR Article 6 Legitimate Interest Assessment documentation, CCPA at-collection disclosure frameworks, Data Protection Impact Assessments (DPIAs) for large-scale processing operations, and automated data retention and purge schedules aligned with each jurisdiction’s legal requirements. In 2026, regulators across the EU have moved explicitly against black-box credit models, mandating Explainable AI (XAI) and full data lineage tracing from source to decision — and Hir Infotech delivers the structured, auditable data pipelines that make that lineage possible. Whether your team operates under FCA rules in the UK, BaFin requirements in Germany, ASIC obligations in Australia, or state-level CCPA extensions in the USA, our compliance-first architecture ensures you collect, store, and use credit data with full defensibility.
Accelerating SME Loan Origination with AI-Scraped Alternative Credit Data
Client Background: A mid-market U.S.-based fintech lender specializing in small business loans, processing approximately 4,000 loan applications per month with a team of 12 underwriters.
Challenge: The client’s underwriting model relied exclusively on FICO scores and bank statements. Over 38% of applications from early-stage businesses and sole proprietors were being declined outright due to thin credit files — not because the borrowers were high-risk, but because the data to assess them simply wasn’t in the model. This was leaving significant revenue on the table and generating borrower dissatisfaction.
Solution: Hir Infotech designed a custom alternative credit data pipeline that scraped business registry filings, Yelp business reviews, BBB accreditation data, LinkedIn company pages, and state court records for each loan applicant. The structured output was delivered via API into the client’s origination platform within 4 hours of each application submission, enriching the underwriting model with 18 additional data signals per file.
Results: Within 6 months of deployment, the client’s approval rate for thin-file applicants increased by 27%. Default rates in the newly approved segment tracked 11% below initial projections, validating the alternative data model’s predictive accuracy. Underwriter time per file dropped from 40 minutes to 12 minutes, enabling the team to handle a 60% increase in monthly application volume without additional headcount.
Client Testimonial: “Hir Infotech didn’t just deliver data — they delivered a competitive advantage. Our model now sees borrowers that were previously invisible to us, and the compliance documentation they provided made our legal team confident from day one.” — VP of Credit Risk, U.S. Fintech Lender
Building a GDPR-Compliant Business Credit Registry Data Feed
Client Background: A mid-tier German commercial bank with operations across Germany, Austria, and Switzerland, running a B2B trade credit program for manufacturing and logistics SMEs.
Challenge: The bank’s credit risk team was manually pulling company data from Handelsregister (German commercial registry) and SCHUFA-adjacent public databases to assess trade credit applicants. The manual process took 3–5 days per company profile and was creating a bottleneck that was slowing down the bank’s SME credit expansion program.
Solution: Hir Infotech built an automated scraping pipeline targeting Handelsregister, the Austrian Firmenbuch, and Swiss Zefix company registries — extracting registration status, director appointments and resignations, filed annual accounts, charges, and insolvency notices. All processing was documented under GDPR Article 6(1)(f) legitimate interest, with full ROPA and DPIA documentation delivered to the client’s DPO.
Results: Company credit profile assembly time fell from 3–5 days to under 6 hours. The bank processed 3,200 additional SME credit applications in the first quarter post-deployment — a 44% increase in throughput. The GDPR compliance package was reviewed by the bank’s legal counsel and required zero revisions.
Client Testimonial: “We were skeptical that a third-party data provider could meet our compliance standards. Hir Infotech’s documentation was more thorough than what our internal team would have produced.” — Head of SME Credit Risk, German Commercial Bank
Enriching a Commercial Credit Scoring Engine with Real-Time Court and Trade Data
Client Background: A UK-based SaaS company providing commercial credit scoring APIs to 200+ SME lenders, invoice finance providers, and trade credit insurers across the UK and Ireland.
Challenge: The platform’s scoring engine relied on Companies House data and manual underwriter inputs. It lacked real-time County Court Judgment (CCJ) data, trade payment performance signals, and director behavioral history — creating scoring gaps that led to mispriced credit products and elevated churn from lender clients who needed richer models.
Solution: Hir Infotech delivered four concurrent data feeds: (1) daily CCJ and insolvency notice scraping from The Gazette and Registry Trust; (2) trade payment performance data from publicly available Creditsafe and Dun & Bradstreet indices; (3) director disqualification notices from Companies House; and (4) sentiment-scored financial news feeds from FT and BBC Business. All feeds were normalized to a unified schema and delivered via REST API with sub-2-hour latency.
Results: The scoring engine’s Gini coefficient improved by 8.4 points following model retraining on the enriched dataset. Lender client churn dropped by 31% in the following two quarters, directly attributed to improved scoring accuracy. The platform was able to launch two new credit products — supply chain finance scoring and director risk scoring — that generated £1.2M in new ARR within the first year.
Client Testimonial: “The data quality and delivery reliability from Hir Infotech is genuinely world-class. We’ve tried three other providers — none came close to this level of structure and accuracy.” — CTO, UK Credit SaaS Platform
Automating SEC and European Regulatory Filing Extraction for Corporate Credit Analysis
Client Background: A Dutch asset management firm with €4.2B AUM in European and U.S. corporate credit, employing 18 credit analysts covering 600+ bond and loan issuers.
Challenge: Analysts were spending 35–40% of their productive time manually downloading, parsing, and summarizing SEC EDGAR filings, Euronext regulatory disclosures, and European Central Bank reports. This manual effort was creating a competitive lag — by the time analysts processed new filings, market-moving credit events had already been priced in by faster, data-driven competitors.
Solution: Hir Infotech deployed an AI-powered document extraction pipeline across SEC EDGAR (10-K, 10-Q, 8-K), AFM (Dutch regulator), AMF (French regulator), and BaFin (German regulator) public disclosure portals. NLP models extracted and structured 42 credit-relevant financial metrics per filing — including leverage ratios, free cash flow, covenant language, and management guidance — and delivered them as structured JSON within 90 minutes of each filing publication.
Results: Analyst time spent on data gathering fell by 68%. The team was able to expand issuer coverage from 600 to 900 companies with no additional headcount. The firm’s credit committee reported a measurable improvement in early warning detection on distressed credits — flagging two covenant breaches 11 days before they were covered by sell-side analysts.
Client Testimonial: “Hir Infotech gave us the same data infrastructure as a bulge-bracket bank’s credit research desk — at a fraction of the cost.” — Head of Credit Research, Dutch Asset Manager
Extracting Property Registry and Mortgage Default Signal Data for Portfolio Risk Management
Client Background: An Australian non-bank mortgage servicer managing a $1.8B residential mortgage portfolio, operating across New South Wales, Victoria, and Queensland.
Challenge: The servicer’s arrears management team was manually monitoring land title registries and court listings for mortgagee-in-possession notices, bankruptcy filings, and property encumbrance changes across their active loan portfolio. The process was consuming 220+ analyst hours per month and was prone to delays of up to 14 days between an event occurring and the team becoming aware.
Solution: Hir Infotech automated monitoring of NSW Land Registry Services, Victorian Land Use Victoria, the Queensland Titles Registry, and the Australian Financial Security Authority (AFSA) bankruptcy database. Alerts for any registered event linked to properties in the client’s portfolio were delivered within 4 hours of publication, with structured data pushed directly into the client’s loan servicing platform.
Results: Event detection latency dropped from 14 days to under 4 hours. The arrears team recovered $3.1M in additional recoveries in the first year by initiating earlier interventions. Monthly analyst hours dedicated to registry monitoring fell from 220 to 18.
Client Testimonial: “The speed and accuracy of Hir Infotech’s monitoring changed how we manage portfolio risk. We respond to events now — not to news from two weeks ago.” — Chief Risk Officer, Australian Non-Bank Mortgage Servicer
Building an AI-Driven Credit Insurance Underwriting Data Platform
Client Background: A Paris-based trade credit insurer providing coverage to 350+ French and European exporters, underwriting approximately €800M in annual credit risk exposure.
Challenge: The underwriting team was relying on annual company accounts and credit agency reports that were often 12–18 months stale by the time they informed underwriting decisions. In a volatile post-COVID trade environment, the team needed real-time signals on buyer financial health — but lacked the technical infrastructure to collect and process them at scale.
Solution: Hir Infotech designed a multi-source credit signal scraping platform covering INPI (France), KvK (Netherlands), Chambers of Commerce (Italy, Spain), payment platform public indices, and business news scrapers across Le Monde Économique, Les Échos, and Handelsblatt. Signals were delivered daily with NLP-derived sentiment scores and structured financial health indicators per buyer entity.
Results: The underwriting team identified 34 high-risk buyer deterioration events in the first 6 months that would have been missed under the previous annual review cycle. Claims reserves were adjusted proactively, avoiding an estimated €6.2M in potential claims losses. Underwriter productivity increased by 40% due to structured data delivery replacing manual research.
Client Testimonial: “Hir Infotech transformed our underwriting from a rear-view mirror to a real-time radar. The value created in the first 6 months alone exceeded our annual contract value many times over.” — Chief Underwriting Officer, French Trade Credit Insurer
Powering a Pan-European SME Credit Health Dashboard with Live Registry Data
Client Background: A Barcelona-based B2B SaaS company providing a credit health monitoring dashboard to 800+ European SMEs and their accountants, with strong user bases in Spain and Italy.
Challenge: The platform needed live, structured SME credit data for Spanish (Registro Mercantil) and Italian (Registro Imprese) companies to power client dashboards. Existing data vendor options were either too expensive for the startup’s unit economics, too slow in refresh rates, or unable to handle the schema normalization across two different national registry systems.
Solution: Hir Infotech built a dual-registry scraping and normalization pipeline covering Registro Mercantil (Spain) and Registro Imprese/Infocamere (Italy) — extracting company status, filed accounts, directors, charges, and insolvency notices. Data was normalized to a unified European company schema and delivered via webhook with 6-hour refresh cycles.
Results: Platform data freshness improved from monthly to 6-hourly. The client onboarded 220 new SME customers in the quarter following the data quality improvement, attributing the growth directly to dashboard accuracy. Infrastructure cost per data record dropped by 63% compared to the previous third-party data vendor.
Client Testimonial: “We went from a data vendor that was slowing us down to a data partner that was accelerating us. Hir Infotech’s team understood our product requirements on day one.” — Co-Founder & CPO, Spanish B2B SaaS Platform
Client Background:
A mid-market B2B SaaS company headquartered in Austin, Texas, offering project management and workflow automation software. The company maintains a sales team of 45 representatives and manages an outbound pipeline targeting operations and IT leaders at companies with 200–2,000 employees.
Challenge:
The client’s CRM contained approximately 180,000 contact records accumulated over five years. Internal audits revealed that 38% of email addresses were bouncing, 24% of phone numbers were disconnected, and over 60% of records were missing firmographic fields like company revenue, employee count, and technology stack data. The SDR team was spending an average of 2.5 hours per day on manual data research, and campaign deliverability had declined significantly, triggering Google Workspace spam flags.
Solution:
Hir Infotech performed a full-scope data append project in three phases: (1) email address verification and re-appending using our AI match engine, (2) direct-dial phone number appending for all SDR-prioritised accounts, and (3) firmographic and technographic enrichment covering revenue bands, employee counts, SIC codes, CRM platform usage, and marketing automation stack for all 180,000 records.
Results:
Client Testimonial:
“Hir Infotech didn’t just clean our data — they fundamentally improved how our sales machine operates. The technographic append alone unlocked a targeting layer we didn’t know we were missing. Our SDRs are faster, our campaigns are cleaner, and the ROI showed up in the first 90 days.”
— VP of Revenue Operations, SaaS Platform, Austin TX
Building a GDPR-Compliant Business Credit Registry Data Feed
Client Background: A mid-tier German commercial bank with operations across Germany, Austria, and Switzerland, running a B2B trade credit program for manufacturing and logistics SMEs.
Challenge: The bank’s credit risk team was manually pulling company data from Handelsregister (German commercial registry) and SCHUFA-adjacent public databases to assess trade credit applicants. The manual process took 3–5 days per company profile and was creating a bottleneck that was slowing down the bank’s SME credit expansion program.
Solution: Hir Infotech built an automated scraping pipeline targeting Handelsregister, the Austrian Firmenbuch, and Swiss Zefix company registries — extracting registration status, director appointments and resignations, filed annual accounts, charges, and insolvency notices. All processing was documented under GDPR Article 6(1)(f) legitimate interest, with full ROPA and DPIA documentation delivered to the client’s DPO.
Results: Company credit profile assembly time fell from 3–5 days to under 6 hours. The bank processed 3,200 additional SME credit applications in the first quarter post-deployment — a 44% increase in throughput. The GDPR compliance package was reviewed by the bank’s legal counsel and required zero revisions.
Client Testimonial: “We were skeptical that a third-party data provider could meet our compliance standards. Hir Infotech’s documentation was more thorough than what our internal team would have produced.” — Head of SME Credit Risk, German Commercial Bank
Enriching a Commercial Credit Scoring Engine with Real-Time Court and Trade Data
Client Background: A UK-based SaaS company providing commercial credit scoring APIs to 200+ SME lenders, invoice finance providers, and trade credit insurers across the UK and Ireland.
Challenge: The platform’s scoring engine relied on Companies House data and manual underwriter inputs. It lacked real-time County Court Judgment (CCJ) data, trade payment performance signals, and director behavioral history — creating scoring gaps that led to mispriced credit products and elevated churn from lender clients who needed richer models.
Solution: Hir Infotech delivered four concurrent data feeds: (1) daily CCJ and insolvency notice scraping from The Gazette and Registry Trust; (2) trade payment performance data from publicly available Creditsafe and Dun & Bradstreet indices; (3) director disqualification notices from Companies House; and (4) sentiment-scored financial news feeds from FT and BBC Business. All feeds were normalized to a unified schema and delivered via REST API with sub-2-hour latency.
Results: The scoring engine’s Gini coefficient improved by 8.4 points following model retraining on the enriched dataset. Lender client churn dropped by 31% in the following two quarters, directly attributed to improved scoring accuracy. The platform was able to launch two new credit products — supply chain finance scoring and director risk scoring — that generated £1.2M in new ARR within the first year.
Client Testimonial: “The data quality and delivery reliability from Hir Infotech is genuinely world-class. We’ve tried three other providers — none came close to this level of structure and accuracy.” — CTO, UK Credit SaaS Platform
Automating SEC and European Regulatory Filing Extraction for Corporate Credit Analysis
Client Background: A Dutch asset management firm with €4.2B AUM in European and U.S. corporate credit, employing 18 credit analysts covering 600+ bond and loan issuers.
Challenge: Analysts were spending 35–40% of their productive time manually downloading, parsing, and summarizing SEC EDGAR filings, Euronext regulatory disclosures, and European Central Bank reports. This manual effort was creating a competitive lag — by the time analysts processed new filings, market-moving credit events had already been priced in by faster, data-driven competitors.
Solution: Hir Infotech deployed an AI-powered document extraction pipeline across SEC EDGAR (10-K, 10-Q, 8-K), AFM (Dutch regulator), AMF (French regulator), and BaFin (German regulator) public disclosure portals. NLP models extracted and structured 42 credit-relevant financial metrics per filing — including leverage ratios, free cash flow, covenant language, and management guidance — and delivered them as structured JSON within 90 minutes of each filing publication.
Results: Analyst time spent on data gathering fell by 68%. The team was able to expand issuer coverage from 600 to 900 companies with no additional headcount. The firm’s credit committee reported a measurable improvement in early warning detection on distressed credits — flagging two covenant breaches 11 days before they were covered by sell-side analysts.
Client Testimonial: “Hir Infotech gave us the same data infrastructure as a bulge-bracket bank’s credit research desk — at a fraction of the cost.” — Head of Credit Research, Dutch Asset Manager
Extracting Property Registry and Mortgage Default Signal Data for Portfolio Risk Management
Client Background: An Australian non-bank mortgage servicer managing a $1.8B residential mortgage portfolio, operating across New South Wales, Victoria, and Queensland.
Challenge: The servicer’s arrears management team was manually monitoring land title registries and court listings for mortgagee-in-possession notices, bankruptcy filings, and property encumbrance changes across their active loan portfolio. The process was consuming 220+ analyst hours per month and was prone to delays of up to 14 days between an event occurring and the team becoming aware.
Solution: Hir Infotech automated monitoring of NSW Land Registry Services, Victorian Land Use Victoria, the Queensland Titles Registry, and the Australian Financial Security Authority (AFSA) bankruptcy database. Alerts for any registered event linked to properties in the client’s portfolio were delivered within 4 hours of publication, with structured data pushed directly into the client’s loan servicing platform.
Results: Event detection latency dropped from 14 days to under 4 hours. The arrears team recovered $3.1M in additional recoveries in the first year by initiating earlier interventions. Monthly analyst hours dedicated to registry monitoring fell from 220 to 18.
Client Testimonial: “The speed and accuracy of Hir Infotech’s monitoring changed how we manage portfolio risk. We respond to events now — not to news from two weeks ago.” — Chief Risk Officer, Australian Non-Bank Mortgage Servicer
Building an AI-Driven Credit Insurance Underwriting Data Platform
Client Background: A Paris-based trade credit insurer providing coverage to 350+ French and European exporters, underwriting approximately €800M in annual credit risk exposure.
Challenge: The underwriting team was relying on annual company accounts and credit agency reports that were often 12–18 months stale by the time they informed underwriting decisions. In a volatile post-COVID trade environment, the team needed real-time signals on buyer financial health — but lacked the technical infrastructure to collect and process them at scale.
Solution: Hir Infotech designed a multi-source credit signal scraping platform covering INPI (France), KvK (Netherlands), Chambers of Commerce (Italy, Spain), payment platform public indices, and business news scrapers across Le Monde Économique, Les Échos, and Handelsblatt. Signals were delivered daily with NLP-derived sentiment scores and structured financial health indicators per buyer entity.
Results: The underwriting team identified 34 high-risk buyer deterioration events in the first 6 months that would have been missed under the previous annual review cycle. Claims reserves were adjusted proactively, avoiding an estimated €6.2M in potential claims losses. Underwriter productivity increased by 40% due to structured data delivery replacing manual research.
Client Testimonial: “Hir Infotech transformed our underwriting from a rear-view mirror to a real-time radar. The value created in the first 6 months alone exceeded our annual contract value many times over.” — Chief Underwriting Officer, French Trade Credit Insurer
Powering a Pan-European SME Credit Health Dashboard with Live Registry Data
Client Background: A Barcelona-based B2B SaaS company providing a credit health monitoring dashboard to 800+ European SMEs and their accountants, with strong user bases in Spain and Italy.
Challenge: The platform needed live, structured SME credit data for Spanish (Registro Mercantil) and Italian (Registro Imprese) companies to power client dashboards. Existing data vendor options were either too expensive for the startup’s unit economics, too slow in refresh rates, or unable to handle the schema normalization across two different national registry systems.
Solution: Hir Infotech built a dual-registry scraping and normalization pipeline covering Registro Mercantil (Spain) and Registro Imprese/Infocamere (Italy) — extracting company status, filed accounts, directors, charges, and insolvency notices. Data was normalized to a unified European company schema and delivered via webhook with 6-hour refresh cycles.
Results: Platform data freshness improved from monthly to 6-hourly. The client onboarded 220 new SME customers in the quarter following the data quality improvement, attributing the growth directly to dashboard accuracy. Infrastructure cost per data record dropped by 63% compared to the previous third-party data vendor.
Client Testimonial: “We went from a data vendor that was slowing us down to a data partner that was accelerating us. Hir Infotech’s team understood our product requirements on day one.” — Co-Founder & CPO, Spanish B2B SaaS Platform
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
With 12+ years of expertise, Hir Infotech has served 2745+ clients globally. Our proven scraping solutions drive B2B success across the USA, Europe, and Australia.
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...

Gain a powerful edge in the 2026 auto market. Leverage automotive data scraping to master dynamic pricing, analyze competitor strategies,...

Unlock smarter investment decisions using real-time LinkedIn data on company growth, talent, and leadership. Gain a critical competitive edge and...

Gain a competitive edge with a powerful News API. This guide explains how it automates data extraction, providing real-time insights...

Unlock powerful aviation intelligence for your travel business. Our 2026 guide to flight data scraping reveals how to track competitor...

Instantly build a powerful recruitment platform by web scraping job boards for thousands of fresh listings. Attract top talent and...
Trusted by 2,745+ clients across the USA, Europe, and Australia, Hir Infotech has spent 13+ years building the credit data infrastructure that lenders, fintechs, insurers, and risk platforms rely on to make faster, more accurate, and fully compliant decisions. Whether you need bureau-enriching alternative data, real-time registry monitoring, or end-to-end credit intelligence pipelines, our team delivers production-ready data in 48 hours.
Experience the Hir Infotech difference — precision, compliance, and scale, built for your credit team.
Access alternative credit signals — court records, business registries, payment behavior data, and financial news — that bureau data alone cannot provide. Build multidimensional borrower risk profiles that reduce blind spots and improve model performance across all credit segments.
Hir Infotech’s credit data extraction covers registries, court systems, and financial platforms across 40+ countries — including the USA, UK, Germany, France, Italy, Spain, the Netherlands, Sweden, Denmark, Austria, Switzerland, Iceland, and Australia — in a single, unified delivery framework.
Alternative credit data scraping enables lenders to assess thin-file borrowers — early-stage businesses, gig workers, new immigrants — who are invisible to traditional bureau models, expanding addressable lending markets without compromising risk discipline.
AI-automated credit data extraction eliminates manual data gathering that typically consumes 35–68% of underwriter time. Deliver structured, enriched borrower profiles in hours rather than days — enabling higher application throughput without additional headcount.
Credit data is delivered via REST API, webhook, SFTP, or direct database push — in JSON, CSV, or XML formats — integrating seamlessly with origination platforms, CRM systems (Salesforce, HubSpot), risk engines, and BI tools (Power BI, Tableau, Snowflake).
Every credit data pipeline delivered by Hir Infotech includes GDPR Article 6 Legitimate Interest Assessments, CCPA disclosure documentation, DPIA records, and automated data purge schedules — ensuring full audit readiness for FCA, BaFin, ASIC, and SEC-regulated clients.
Continuous monitoring pipelines track insolvency filings, CCJ registrations, director changes, and covenant breach signals in near real-time — enabling proactive portfolio management and early intervention before losses materialize.
Enriching ML-based credit scoring models with scraped alternative data signals has been shown to improve Gini coefficients by 5–10+ points — directly translating to lower default rates, better risk pricing, and improved portfolio profitability for lenders and insurers.
Custom-scraped credit data pipelines from Hir Infotech deliver 40–65% cost savings compared to traditional bureau data subscriptions and enterprise data vendor contracts — with no per-record licensing fees, making high-volume use cases economically viable.
Hir Infotech offers white-label credit data feeds and embedded API solutions for SaaS platforms, enabling product teams to launch credit intelligence features under their own brand — powered by Hir Infotech’s extraction and normalization infrastructure.
At Hir Infotech, we offer flexible pricing models to power your data-driven success. Choose Subscription-Based Pricing for ongoing scraping needs with predictable costs, Pay-As-You-Go for one-off tasks billed by usage, Project-Based Flat Fees for tailored, end-to-end solutions, or Hourly Pricing for custom development and complex challenges. Whatever your budget or project scope, our expert team delivers cost-effective, high-quality web scraping solutions designed to fit your needs.

A one-time fee is charged for a specific project, regardless of volume or duration, based on scope and complexity.
Billed based on the time spent developing, running, or maintaining the scraper, often used for custom or consulting-heavy projects.

Charged based on actual usage, such as per request, per GB of bandwidth, or per page scraped, with no fixed commitment.
pay a recurring fee (monthly or annually) for access to scraping services, often tiered based on usage limits like the number of requests, pages scraped, or data points extracted.
We begin by collaborating with you to define your data needs—be it for a one-time project, recurring insights, or custom solutions. Whether you opt for Pay-As-You-Go flexibility, a Project-Based Flat Fee, Hourly expertise, or a Subscription plan, we align our approach to your objectives.
Our team identifies the websites and data sources critical to your project. We analyze site structures, assess complexity (e.g., static vs. dynamic content), and plan the most efficient scraping strategy, ensuring compliance with public data access norms.
Using cutting-edge tools and custom-built scrapers, we extract data at scale. We tackle challenges like JavaScript-rendered pages or anti-scraping measures with techniques such as:
Raw data is parsed, cleaned, and structured into formats like CSV, JSON, or Excel. We remove duplicates, correct errors, and validate accuracy to ensure you receive reliable, ready-to-use datasets.
Depending on your pricing model, we deliver results how and when you need them:
We monitor site changes, adapt scrapers as needed, and provide support to keep your data flowing seamlessly. Subscription clients enjoy continuous updates, while Hourly clients benefit from hands-on refinements.
Hir Infotech extracts a broad spectrum of credit-relevant data including business registry filings, annual accounts, director and shareholder information, court judgments and liens, insolvency and bankruptcy notices, trade credit payment indices, regulatory disclosures (SEC, FCA, BaFin, ASIC), alternative financial signals from review platforms, and macro-economic news signals. Data is sourced from 500+ public and semi-public sources across the USA, UK, Germany, France, Italy, Spain, the Netherlands, Sweden, Austria, Switzerland, Denmark, Iceland, and Australia, delivered in structured, model-ready formats.
Every credit data engagement includes a documented GDPR Legitimate Interest Assessment (LIA) under Article 6(1)(f), a Data Protection Impact Assessment (DPIA) for large-scale operations, Records of Processing Activities (ROPA) documentation, automated data retention and purge schedules, and CCPA at-collection disclosure frameworks. All pipelines are reviewed by compliance specialists before deployment. Enterprise clients receive the full compliance documentation package for their own DPO and legal review — ensuring audit readiness with zero additional effort.
For standard credit registry and court data scraping engagements, Hir Infotech typically delivers the first structured dataset within 48–72 hours of project kickoff. For complex, multi-source alternative credit data pipelines with API integration, full deployment typically takes 5–10 business days. Ongoing refresh cycles operate at frequencies from 6-hourly to real-time event monitoring, depending on the source and client requirement.
Yes. Hir Infotech delivers credit data via REST API, webhook, SFTP, or direct database push in JSON, CSV, XML, or custom schemas. Our engineering team maps output fields to your existing data model, eliminating transformation overhead on your side. We have successfully integrated with platforms including Salesforce Financial Services Cloud, nCino, Temenos, Mambu, and custom-built Python/R-based credit scoring frameworks.
Bureau subscriptions provide standardized, backward-looking data for a limited borrower universe. Generic data marketplaces offer pre-collected, often stale datasets with no customization. Hir Infotech builds bespoke, real-time credit data pipelines tailored to your specific borrower population, geography, and risk model inputs — with compliance documentation, direct API integration, and dedicated account management. You get exactly the data your model needs, from the sources that matter most to your portfolio, at a fraction of enterprise bureau licensing costs.
Yes. Hir Infotech has delivered credit data infrastructure to clients operating simultaneously under FCA (UK), BaFin (Germany), AMF (France), CNMV (Spain), Banca d’Italia, AFM (Netherlands), ASIC (Australia), and SEC/CFPB (USA) regulatory frameworks. Our compliance architecture is designed to be jurisdiction-layered — each data pipeline carries the appropriate documentation for each applicable regulatory regime, so multi-market lenders and credit insurers receive unified data with jurisdiction-specific compliance coverage.
Hir Infotech maintains a 99.2% extraction accuracy rate across credit data pipelines, validated through automated schema verification, cross-source reconciliation, and human quality review for high-value datasets. Data freshness is managed through configurable refresh cycles — from 6-hourly registry scraping to sub-2-hour regulatory filing extraction — ensuring your risk models operate on the most current available signals rather than stale, pre-purchased datasets.
Absolutely. Hir Infotech serves a diverse range of credit-adjacent use cases including trade credit insurance underwriting, invoice finance risk assessment, supply chain finance credit scoring, bonding and surety underwriting, and corporate bond analysis. Any business function that requires structured financial health data on counterparties — buyers, suppliers, borrowers, or bond issuers — can leverage our extraction and intelligence capabilities.
Hir Infotech operates enterprise-grade extraction infrastructure including headless browser automation, residential and datacenter proxy rotation, CAPTCHA resolution services, and intelligent retry logic. In the event of a structural site change, our engineering team detects the break automatically through output validation monitoring and deploys a revised extraction schema within 4–8 business hours — ensuring minimal pipeline disruption with no action required from the client’s side.
ROI varies by use case, but typical outcomes reported by Hir Infotech clients include: 27–44% increase in application approval rates for thin-file segments; 40–68% reduction in analyst time per credit file; 30–63% cost reduction versus existing data vendor contracts; and measurable improvements in credit model Gini coefficients of 5–10+ points. Most enterprise clients report payback periods of 2–4 months on their Hir Infotech credit data investment.
+91 99099 90610
+91 94096 28528
inquiry@hirinfotech.com