
29-January-2026
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...
Hir Infotech is a globally recognized AI-driven data collection company with 13+ years of experience delivering structured, accurate, and compliance-ready data to B2B enterprises across the USA, Europe, and Australia. From real-time web extraction to large-scale structured dataset delivery, we power smarter decisions for 2,745+ satisfied clients worldwide. Whether you’re a CTO scaling competitive intelligence pipelines or a Chief Data Officer demanding GDPR-compliant data feeds, Hir Infotech is the trusted partner that transforms the open web into your most valuable business asset.


10B+
Data Points Delivered
99.5%+
Data Accuracy Rate
2,745+
Happy Clients
13+
Years of Expertise
50+
Countries Served
In 2026, data collection has evolved from a supporting function into the strategic foundation of every high-performing B2B enterprise. Organizations that harness structured, high-quality, real-time data consistently outpace competitors in market responsiveness, lead conversion, and operational efficiency. Whether your teams are tracking competitor pricing across European markets, building ML training datasets, monitoring regulatory changes in the USA, or identifying emerging consumer demand signals in Australia — the speed, accuracy, and compliance of your data pipeline directly determines the quality of every downstream business decision. At Hir Infotech, we go beyond simple scraping. Our AI-assisted data collection workflows combine intelligent crawlers, machine learning validation, proxy management, and human QA to deliver structured, clean, and actionable datasets — tailored to your industry, your use case, and your compliance requirements. With 13+ years of experience and 2,745+ happy clients spanning North America, the UK, Germany, France, the Netherlands, Sweden, Switzerland, Austria, Denmark, Spain, Italy, Iceland, and Australia, our global data collection capabilities are built to scale with your ambitions.
Hir Infotech’s end-to-end data collection infrastructure combines proprietary AI models, distributed proxy networks, and human-in-the-loop validation to deliver enterprise-grade datasets at scale — reliably, rapidly, and in full regulatory compliance.
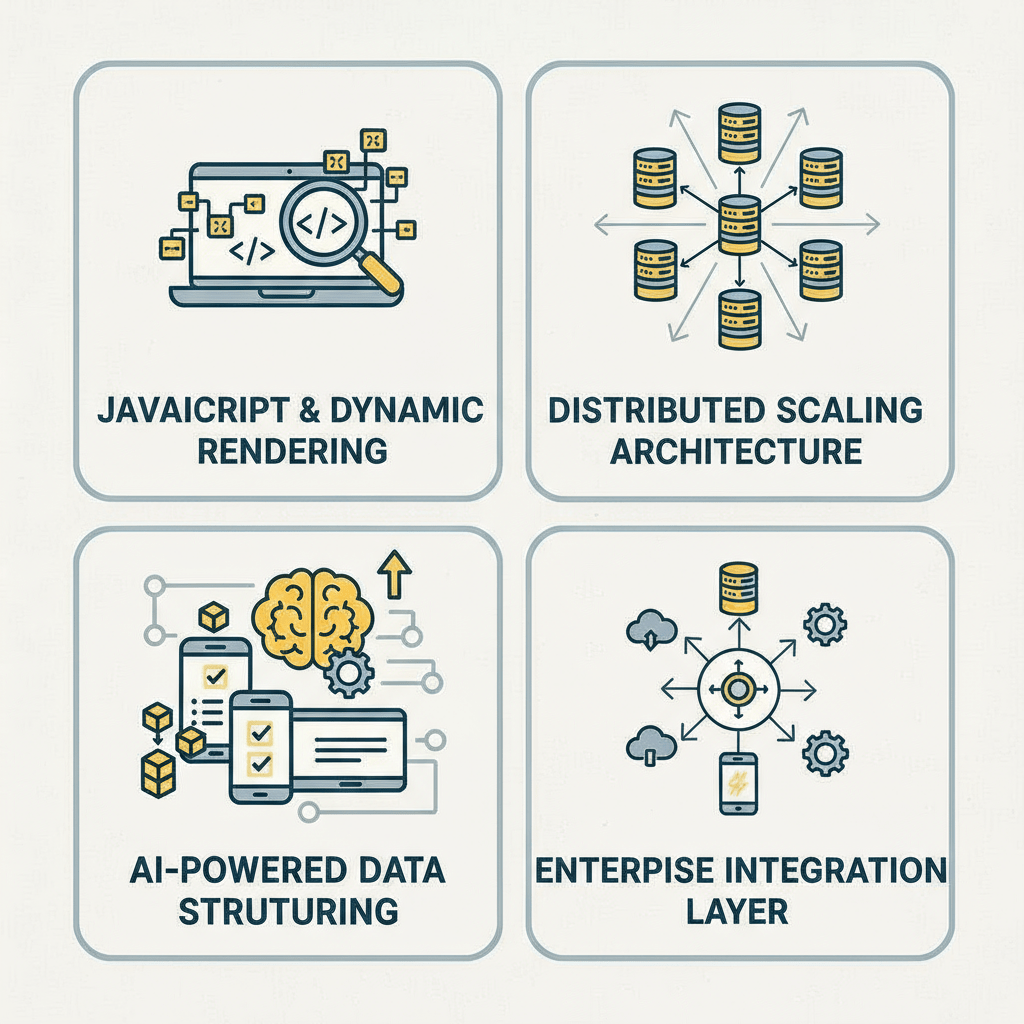
Our AI models dynamically rotate residential and datacenter proxies, simulate genuine browser sessions, and solve CAPTCHAs with near-zero failure rates, ensuring maximum data access even from the most protection-heavy enterprise platforms and directories.
Our pipelines simultaneously collect data from multiple sources — websites, APIs, PDFs, and structured web portals — then apply AI-driven deduplication and normalization rules, delivering a single, unified dataset free of redundancy and inconsistency.
Modern websites render data through JS frameworks and single-page applications. Hir Infotech’s headless browser infrastructure captures fully rendered page content — ensuring no data is missed due to dynamic loading, lazy rendering, or AJAX-based content injection.
Every data collection task generates a complete audit trail: source URLs, collection timestamps, transformation logs, and delivery records. This governance layer ensures your data is fully traceable — satisfying GDPR, CCPA, and ISO compliance requirements across EU, US, and Australian jurisdictions.
















Amazon hosts hundreds of millions of product listings with real-time pricing, reviews, and seller data. B2B procurement teams, retailers, and brands collect Amazon data to benchmark pricing strategies, monitor competitor movements, track Buy Box ownership, and optimize product positioning in competitive categories.
LinkedIn is the world’s largest professional network and a goldmine for B2B lead generation. Sales and marketing teams extract company profiles, decision-maker contacts, job titles, industry tags, and company size data to build hyper-targeted outreach lists aligned with ideal customer profiles.
Yelp contains verified business listings, customer reviews, ratings, hours, and location data for millions of US businesses. B2B data teams in market research, franchise management, and local SEO collect Yelp data to analyze competitive landscapes, reputation trends, and geographic market penetration across American cities.
Kompass is a premier pan-European B2B directory covering companies across Germany, France, Spain, Italy, the Netherlands, and beyond. Enterprises collect Kompass data for supplier discovery, partner identification, territory mapping, and cross-border market entry research with verified company financials and contact records.
Rightmove is the UK’s leading property portal, containing millions of residential and commercial listings with pricing, location, and property attributes. PropTech companies, investment firms, and UK market researchers collect Rightmove data to power valuation models, investment analysis, and rental market intelligence.
SEEK is Australia’s dominant job marketplace, listing hundreds of thousands of active roles across all industries. HR technology providers, workforce analytics teams, and talent intelligence platforms extract SEEK data to map hiring trends, salary benchmarks, skills demand signals, and competitor talent acquisition strategies across Australian metro and regional markets.
Google News aggregates real-time headlines and articles from thousands of news sources worldwide. B2B enterprises in finance, legal, and PR collect news data for brand monitoring, competitive intelligence, regulatory change tracking, and sentiment analysis — enabling rapid response to market-moving events.
Booking.com hosts real-time hotel availability, room rates, review scores, and property attributes across 220+ countries. Travel analytics companies, revenue management platforms, and hospitality chains collect Booking.com data to power dynamic pricing models, market positioning tools, and competitive rate benchmarking systems.
PubMed contains millions of peer-reviewed medical and life sciences publications. Pharmaceutical companies, biotech firms, and healthcare AI platforms collect PubMed data to track clinical trial outcomes, emerging research trends, drug development pipelines, and competitive landscape shifts across global therapeutic areas.
For B2B companies operating in competitive markets across the USA, UK, Germany, France, and the Netherlands, having access to timely and accurate competitor data is not optional — it is existential. Hir Infotech’s AI-driven data collection services empower commercial intelligence teams to monitor competitor pricing, product catalog changes, marketing messaging, and market positioning — all in real time, at scale, and with zero manual effort. Our clients in the retail, SaaS, and financial services sectors across these geographies consistently report 40–60% reductions in market research cycle times after deploying our data pipelines, replacing patchwork manual processes with structured, automated, and continuously refreshed data assets delivered directly into their analytics stacks. With deep regional expertise in European data regulations including GDPR and the UK’s evolving post-Brexit data frameworks, Hir Infotech ensures every extraction engagement is fully compliant — so your legal and privacy teams can stay focused on strategy, not remediation.
Generating high-quality, verified B2B leads at scale is one of the most persistent challenges for revenue teams in Australia, Sweden, Denmark, Austria, Switzerland, Spain, Italy, and Iceland. Hir Infotech’s custom B2B data collection services extract structured company records, decision-maker contact data, industry classifications, firmographic attributes, and technographic signals from directories, professional networks, and company websites — then validate, deduplicate, and enrich them into sales-ready prospect lists. Our lead data pipelines integrate directly with CRM platforms including Salesforce, HubSpot, Pipedrive, and Microsoft Dynamics — meaning your sales development representatives receive fresh, actionable intelligence without ever leaving their workflow. With 2,745+ happy clients across three continents and 13+ years of experience delivering compliant, high-accuracy B2B datasets, Hir Infotech is the trusted data partner for revenue teams that refuse to compete on stale information.
Client Background: A mid-market specialty retail chain operating 80+ stores across the US Midwest and an expanding e-commerce presence, with a merchandising team struggling to respond to rapid competitor price changes on Amazon, Walmart, and direct-brand DTC sites.
Challenge: The client’s pricing team was manually checking competitor pricing three times per week using spreadsheets. This process consumed 40+ hours per week of analyst time, produced data that was already 48–72 hours stale, and created blind spots across key categories during high-velocity promotional periods like Black Friday and back-to-school season.
Solution: Hir Infotech deployed a custom AI-driven data collection pipeline targeting 12 competitor domains and 3 major marketplace platforms. Our smart crawlers extracted SKU-level pricing, promotional flags, bundle configurations, and availability data every 4 hours — 24/7 — with intelligent anti-bot bypass ensuring uninterrupted access. Data was delivered via API directly into the client’s existing pricing management platform.
Results:
Client Testimonial: “Hir Infotech’s data collection pipeline fundamentally changed how we compete on price. We went from reacting to the market three days late to setting the pace in our categories. The accuracy and reliability of their data is genuinely world-class.” — VP of Merchandising, US Retail Chain
Client Background: A fast-growing B2B SaaS platform based in Munich, Germany, serving mid-market manufacturing and logistics companies across the DACH region (Germany, Austria, Switzerland). Their sales team needed a scalable pipeline of verified decision-maker contacts to support an aggressive expansion into new verticals.
Challenge: Previous list-purchasing attempts had yielded poor data quality — incorrect email addresses, outdated job titles, and critically, records of questionable GDPR compliance provenance. The company’s DPO had halted all outbound campaigns pending a compliant, auditable data sourcing solution.
Solution: Hir Infotech designed a GDPR-aligned data collection workflow targeting publicly available business directories, trade association websites, and company registers in Germany, Austria, and Switzerland. Our team collected company records, then enriched and validated contact information through multi-layer verification — with full source attribution, collection timestamps, and a lawful basis documentation package delivered alongside every dataset.
Results:
Client Testimonial: “We needed data we could actually use — legally and practically. Hir Infotech didn’t just deliver records; they delivered a compliance framework around those records that gave our legal team full confidence. That level of diligence is rare.” — Chief Revenue Officer, Munich B2B SaaS Company
Client Background: A London-based alternative asset management firm running event-driven trading strategies across European equities and credit markets. Their research team required continuous, structured extraction of financial news, earnings announcements, and regulatory filings from hundreds of sources across the EU and UK.
Challenge: The firm’s existing news aggregation tooling was missing key sources, introducing 15–25 minute latency between publication and delivery, and failing to extract structured entities — companies, instruments, jurisdictions — in a machine-readable format compatible with their quantitative models.
Solution: Hir Infotech built a custom real-time data collection architecture covering 340+ financial news sources, regulatory portals (FCA, ESMA, BaFin), and company IR pages. Our AI pipelines extracted, normalized, and tagged each article with entity metadata — company names, tickers, event types, sentiment signals, and geographic jurisdiction — and delivered structured JSON feeds with sub-5-minute latency via WebSocket API.
Results:
Client Testimonial: “The speed and structure of Hir Infotech’s data feeds gave our quant team a genuine informational edge. Their coverage of European regulatory sources is particularly impressive — we’re getting structured, machine-readable data from sources no other provider was capturing.” — Head of Quantitative Research, London Asset Manager
Client Background: A Sydney-based PropTech startup building an AI-powered property investment intelligence platform for retail and professional investors across Australia’s major metro and regional markets. The product required comprehensive, current, and structured property listing data.
Challenge: The client needed structured data from multiple Australian property portals — including listing prices, property attributes, suburb-level median pricing, days on market, and agent data — refreshed daily across all Australian states and territories. Existing data licensing options were cost-prohibitive, and manual scraping attempts had been blocked repeatedly.
Solution: Hir Infotech deployed a multi-portal data collection system across four major Australian property platforms, using rotating residential proxy infrastructure to maintain reliable access. Our pipelines extracted, normalized, and cross-referenced property data daily — delivering a unified, clean dataset via PostgreSQL-compatible API with full suburb and postcode geographic tagging.
Results:
Client Testimonial: “Hir Infotech made our data infrastructure possible. We went from zero to a production-ready property data pipeline in six weeks. Their team’s technical depth and willingness to solve genuinely hard collection problems made them feel like an extension of our own engineering team.” — Co-Founder & CTO, Sydney PropTech Startup
Client Background: A Paris-based B2B procurement intelligence platform serving procurement directors at large French and pan-European enterprises in the automotive, aerospace, and industrial manufacturing sectors.
Challenge: The client needed continuously updated supplier capability data, certifications, financial health signals, and contact information from thousands of European industrial suppliers across France, Italy, Spain, Germany, and the Netherlands — data that was highly fragmented across trade directories, company websites, and national business registries.
Solution: Hir Infotech designed a multi-country data collection orchestration covering 18 European data sources — including Kompass, national trade registers, and industry association portals. AI-driven entity resolution matched supplier records across sources to create unified, deduplicated profiles for 280,000+ European industrial suppliers, updated on a weekly basis with change detection and delta-delivery alerts.
Results:
Client Testimonial: “Our product was only as good as the supplier data behind it. Hir Infotech solved a data collection problem we had been struggling with for two years. Their multi-country, multi-source approach is genuinely unique — no other provider could match their European coverage.” — Chief Product Officer, Paris Procurement Platform
Client Background: A Boston-based life sciences analytics company providing competitive intelligence software to pharmaceutical and biotech R&D teams across the USA and Europe. Their platform required continuous collection of clinical trial data, drug approval filings, and scientific publication metadata.
Challenge: The client needed structured data from ClinicalTrials.gov, EudraCT, PubMed, FDA drug databases, and EMA approval portals — collected, normalized, and cross-referenced across entities like drug names, conditions, trial phases, and sponsor organizations. Manual curation had become unsustainable as their platform scaled.
Solution: Hir Infotech built a specialized life sciences data collection pipeline targeting 8 authoritative global healthcare data sources. Our AI models extracted and structured trial records, publication metadata, approval timelines, and competitor pipeline signals — then applied entity resolution to link drug names, INN codes, company identifiers, and therapeutic area classifications into a unified knowledge graph updated daily.
Results:
Client Testimonial: “In life sciences intelligence, data quality and timeliness are everything. Hir Infotech’s team understood the domain deeply — they didn’t just collect data, they understood what the data meant and structured it accordingly. The quality of their output exceeded anything we had built internally.” — Director of Data Products, Boston Life Sciences Analytics Company
Client Background: A Stockholm-based multi-category online retailer operating across Sweden, Denmark, Norway, and Finland, competing against both local players and pan-European e-commerce giants across consumer electronics, home goods, and fashion categories.
Challenge: The retailer’s category management team needed daily competitor catalog data — product titles, descriptions, attributes, pricing, promotional activity, and customer review scores — across 15 competitor domains. Existing manual monitoring was covering less than 5% of the competitive universe and producing unreliable data due to website structure changes.
Solution: Hir Infotech deployed a self-healing data collection architecture with adaptive crawlers that automatically detect and accommodate website structural changes. The solution covered 15 competitor domains across 5 Nordic countries, extracting 2.3 million product records daily with AI-powered attribute normalization mapping disparate competitor data schemas into a unified product taxonomy.
Results:
Client Testimonial: “We were essentially blind to our competition before Hir Infotech. Now we have a live view of everything happening in our market — pricing, promotions, new product launches — updated every day. The ROI was visible within the first month.” — Head of Category Management, Stockholm E-Commerce Retailer
Client Background:
A mid-market B2B SaaS company headquartered in Austin, Texas, offering project management and workflow automation software. The company maintains a sales team of 45 representatives and manages an outbound pipeline targeting operations and IT leaders at companies with 200–2,000 employees.
Challenge:
The client’s CRM contained approximately 180,000 contact records accumulated over five years. Internal audits revealed that 38% of email addresses were bouncing, 24% of phone numbers were disconnected, and over 60% of records were missing firmographic fields like company revenue, employee count, and technology stack data. The SDR team was spending an average of 2.5 hours per day on manual data research, and campaign deliverability had declined significantly, triggering Google Workspace spam flags.
Solution:
Hir Infotech performed a full-scope data append project in three phases: (1) email address verification and re-appending using our AI match engine, (2) direct-dial phone number appending for all SDR-prioritised accounts, and (3) firmographic and technographic enrichment covering revenue bands, employee counts, SIC codes, CRM platform usage, and marketing automation stack for all 180,000 records.
Results:
Client Testimonial:
“Hir Infotech didn’t just clean our data — they fundamentally improved how our sales machine operates. The technographic append alone unlocked a targeting layer we didn’t know we were missing. Our SDRs are faster, our campaigns are cleaner, and the ROI showed up in the first 90 days.”
— VP of Revenue Operations, SaaS Platform, Austin TX
Client Background: A fast-growing B2B SaaS platform based in Munich, Germany, serving mid-market manufacturing and logistics companies across the DACH region (Germany, Austria, Switzerland). Their sales team needed a scalable pipeline of verified decision-maker contacts to support an aggressive expansion into new verticals.
Challenge: Previous list-purchasing attempts had yielded poor data quality — incorrect email addresses, outdated job titles, and critically, records of questionable GDPR compliance provenance. The company’s DPO had halted all outbound campaigns pending a compliant, auditable data sourcing solution.
Solution: Hir Infotech designed a GDPR-aligned data collection workflow targeting publicly available business directories, trade association websites, and company registers in Germany, Austria, and Switzerland. Our team collected company records, then enriched and validated contact information through multi-layer verification — with full source attribution, collection timestamps, and a lawful basis documentation package delivered alongside every dataset.
Results:
Client Testimonial: “We needed data we could actually use — legally and practically. Hir Infotech didn’t just deliver records; they delivered a compliance framework around those records that gave our legal team full confidence. That level of diligence is rare.” — Chief Revenue Officer, Munich B2B SaaS Company
Client Background: A London-based alternative asset management firm running event-driven trading strategies across European equities and credit markets. Their research team required continuous, structured extraction of financial news, earnings announcements, and regulatory filings from hundreds of sources across the EU and UK.
Challenge: The firm’s existing news aggregation tooling was missing key sources, introducing 15–25 minute latency between publication and delivery, and failing to extract structured entities — companies, instruments, jurisdictions — in a machine-readable format compatible with their quantitative models.
Solution: Hir Infotech built a custom real-time data collection architecture covering 340+ financial news sources, regulatory portals (FCA, ESMA, BaFin), and company IR pages. Our AI pipelines extracted, normalized, and tagged each article with entity metadata — company names, tickers, event types, sentiment signals, and geographic jurisdiction — and delivered structured JSON feeds with sub-5-minute latency via WebSocket API.
Results:
Client Testimonial: “The speed and structure of Hir Infotech’s data feeds gave our quant team a genuine informational edge. Their coverage of European regulatory sources is particularly impressive — we’re getting structured, machine-readable data from sources no other provider was capturing.” — Head of Quantitative Research, London Asset Manager
Client Background: A Sydney-based PropTech startup building an AI-powered property investment intelligence platform for retail and professional investors across Australia’s major metro and regional markets. The product required comprehensive, current, and structured property listing data.
Challenge: The client needed structured data from multiple Australian property portals — including listing prices, property attributes, suburb-level median pricing, days on market, and agent data — refreshed daily across all Australian states and territories. Existing data licensing options were cost-prohibitive, and manual scraping attempts had been blocked repeatedly.
Solution: Hir Infotech deployed a multi-portal data collection system across four major Australian property platforms, using rotating residential proxy infrastructure to maintain reliable access. Our pipelines extracted, normalized, and cross-referenced property data daily — delivering a unified, clean dataset via PostgreSQL-compatible API with full suburb and postcode geographic tagging.
Results:
Client Testimonial: “Hir Infotech made our data infrastructure possible. We went from zero to a production-ready property data pipeline in six weeks. Their team’s technical depth and willingness to solve genuinely hard collection problems made them feel like an extension of our own engineering team.” — Co-Founder & CTO, Sydney PropTech Startup
Client Background: A Paris-based B2B procurement intelligence platform serving procurement directors at large French and pan-European enterprises in the automotive, aerospace, and industrial manufacturing sectors.
Challenge: The client needed continuously updated supplier capability data, certifications, financial health signals, and contact information from thousands of European industrial suppliers across France, Italy, Spain, Germany, and the Netherlands — data that was highly fragmented across trade directories, company websites, and national business registries.
Solution: Hir Infotech designed a multi-country data collection orchestration covering 18 European data sources — including Kompass, national trade registers, and industry association portals. AI-driven entity resolution matched supplier records across sources to create unified, deduplicated profiles for 280,000+ European industrial suppliers, updated on a weekly basis with change detection and delta-delivery alerts.
Results:
Client Testimonial: “Our product was only as good as the supplier data behind it. Hir Infotech solved a data collection problem we had been struggling with for two years. Their multi-country, multi-source approach is genuinely unique — no other provider could match their European coverage.” — Chief Product Officer, Paris Procurement Platform
Client Background: A Boston-based life sciences analytics company providing competitive intelligence software to pharmaceutical and biotech R&D teams across the USA and Europe. Their platform required continuous collection of clinical trial data, drug approval filings, and scientific publication metadata.
Challenge: The client needed structured data from ClinicalTrials.gov, EudraCT, PubMed, FDA drug databases, and EMA approval portals — collected, normalized, and cross-referenced across entities like drug names, conditions, trial phases, and sponsor organizations. Manual curation had become unsustainable as their platform scaled.
Solution: Hir Infotech built a specialized life sciences data collection pipeline targeting 8 authoritative global healthcare data sources. Our AI models extracted and structured trial records, publication metadata, approval timelines, and competitor pipeline signals — then applied entity resolution to link drug names, INN codes, company identifiers, and therapeutic area classifications into a unified knowledge graph updated daily.
Results:
Client Testimonial: “In life sciences intelligence, data quality and timeliness are everything. Hir Infotech’s team understood the domain deeply — they didn’t just collect data, they understood what the data meant and structured it accordingly. The quality of their output exceeded anything we had built internally.” — Director of Data Products, Boston Life Sciences Analytics Company
Client Background: A Stockholm-based multi-category online retailer operating across Sweden, Denmark, Norway, and Finland, competing against both local players and pan-European e-commerce giants across consumer electronics, home goods, and fashion categories.
Challenge: The retailer’s category management team needed daily competitor catalog data — product titles, descriptions, attributes, pricing, promotional activity, and customer review scores — across 15 competitor domains. Existing manual monitoring was covering less than 5% of the competitive universe and producing unreliable data due to website structure changes.
Solution: Hir Infotech deployed a self-healing data collection architecture with adaptive crawlers that automatically detect and accommodate website structural changes. The solution covered 15 competitor domains across 5 Nordic countries, extracting 2.3 million product records daily with AI-powered attribute normalization mapping disparate competitor data schemas into a unified product taxonomy.
Results:
Client Testimonial: “We were essentially blind to our competition before Hir Infotech. Now we have a live view of everything happening in our market — pricing, promotions, new product launches — updated every day. The ROI was visible within the first month.” — Head of Category Management, Stockholm E-Commerce Retailer
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
With 12+ years of expertise, Hir Infotech has served 2745+ clients globally. Our proven scraping solutions drive B2B success across the USA, Europe, and Australia.
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...

Gain a powerful edge in the 2026 auto market. Leverage automotive data scraping to master dynamic pricing, analyze competitor strategies,...

Unlock smarter investment decisions using real-time LinkedIn data on company growth, talent, and leadership. Gain a critical competitive edge and...

Gain a competitive edge with a powerful News API. This guide explains how it automates data extraction, providing real-time insights...

Unlock powerful aviation intelligence for your travel business. Our 2026 guide to flight data scraping reveals how to track competitor...

Instantly build a powerful recruitment platform by web scraping job boards for thousands of fresh listings. Attract top talent and...
For 13+ years, Hir Infotech has been the trusted data collection partner for 2,745+ B2B companies across the USA, Europe, and Australia — delivering accurate, structured, and compliance-ready datasets that power smarter decisions, faster pipelines, and stronger competitive positions.
Whether you need a sample dataset to validate our quality, a pilot project to test a new use case, or a full-scale data intelligence partnership — we’re ready to deliver. Request your free sample dataset today and experience the Hir Infotech difference firsthand.
Hir Infotech — 13+ Years | 2,745+ Happy Clients | USA · Europe · Australia
Access continuously refreshed, structured data from competitor websites, industry portals, and market sources — empowering commercial teams to respond to market shifts, price changes, and emerging trends in hours, not weeks.
Structured datasets delivered via REST API, SFTP, direct database connection, or cloud storage — pre-mapped to your CRM (Salesforce, HubSpot), data warehouse (Snowflake, BigQuery, Redshift), or BI platform for zero-friction ingestion and immediate operationalization.
Go beyond one-time data pulls with persistent monitoring pipelines that detect and deliver only changed records — flagging price updates, new product listings, leadership changes, and news events in real time so your teams act on fresh signals, not historical snapshots.
Collect verified, enriched B2B contact and company data at massive scale — enabling sales and marketing teams to build high-quality prospect pipelines without manual research, reducing cost-per-lead by up to 60% versus traditional list purchasing.
Replacing manual data research and fragmented vendor relationships with a single, automated Hir Infotech data pipeline typically reduces data acquisition costs by 45–70% while increasing data freshness and coverage simultaneously — delivering measurable ROI within the first quarter.
Every data collection engagement includes source attribution, lawful basis documentation, and audit trail records — ensuring your organization meets GDPR obligations in the EU and CCPA requirements in California without risk of regulatory exposure or costly fines.
Collect structured data from any public web source across 50+ countries — including region-specific directories, national business registries, trade portals, and e-commerce platforms in the USA, UK, Germany, France, Australia, Sweden, Netherlands, Switzerland, and beyond — from one integrated partner.
Multi-layer validation combining AI anomaly detection, schema enforcement, and human QA review ensures your datasets arrive at 99.5%+ accuracy — eliminating the garbage-in-garbage-out problem that undermines ML models, BI dashboards, and strategic decisions.
Unlike generic data providers, Hir Infotech builds collection pipelines to your exact data schema requirements — delivering precisely structured records mapped to your taxonomy, with custom field naming, nested object support, and relational linking that eliminates post-delivery transformation work.
Every engagement is backed by a dedicated data engineering team, transparent project communication, and contractual SLA guarantees — ensuring 98.7%+ on-time delivery, proactive issue resolution, and a true long-term partnership rather than a transactional vendor relationship.
At Hir Infotech, we offer flexible pricing models to power your data-driven success. Choose Subscription-Based Pricing for ongoing scraping needs with predictable costs, Pay-As-You-Go for one-off tasks billed by usage, Project-Based Flat Fees for tailored, end-to-end solutions, or Hourly Pricing for custom development and complex challenges. Whatever your budget or project scope, our expert team delivers cost-effective, high-quality web scraping solutions designed to fit your needs.

A one-time fee is charged for a specific project, regardless of volume or duration, based on scope and complexity.
Billed based on the time spent developing, running, or maintaining the scraper, often used for custom or consulting-heavy projects.

Charged based on actual usage, such as per request, per GB of bandwidth, or per page scraped, with no fixed commitment.
pay a recurring fee (monthly or annually) for access to scraping services, often tiered based on usage limits like the number of requests, pages scraped, or data points extracted.
We begin by collaborating with you to define your data needs—be it for a one-time project, recurring insights, or custom solutions. Whether you opt for Pay-As-You-Go flexibility, a Project-Based Flat Fee, Hourly expertise, or a Subscription plan, we align our approach to your objectives.
Our team identifies the websites and data sources critical to your project. We analyze site structures, assess complexity (e.g., static vs. dynamic content), and plan the most efficient scraping strategy, ensuring compliance with public data access norms.
Using cutting-edge tools and custom-built scrapers, we extract data at scale. We tackle challenges like JavaScript-rendered pages or anti-scraping measures with techniques such as:
Raw data is parsed, cleaned, and structured into formats like CSV, JSON, or Excel. We remove duplicates, correct errors, and validate accuracy to ensure you receive reliable, ready-to-use datasets.
Depending on your pricing model, we deliver results how and when you need them:
We monitor site changes, adapt scrapers as needed, and provide support to keep your data flowing seamlessly. Subscription clients enjoy continuous updates, while Hourly clients benefit from hands-on refinements.
B2B data collection is the systematic process of identifying, extracting, structuring, validating, and delivering data from publicly accessible web sources to support specific business intelligence, lead generation, or operational objectives. Unlike generic web scraping — which simply pulls raw HTML — professional B2B data collection involves AI-powered extraction pipelines, schema-mapped output, multi-layer validation, GDPR/CCPA compliance frameworks, and delivery integrations. At Hir Infotech, data collection is a managed intelligence service, not a commodity utility — every engagement is designed around your business outcomes, data architecture, and compliance requirements.
GDPR compliance is embedded into every stage of our data collection workflows for EU clients. We collect only publicly available data with documented source URLs and collection timestamps, apply data minimization principles, exclude personal data fields where not required, provide complete lawful basis documentation packages, and generate full audit trail records. We stay continuously updated with GDPR enforcement developments including the EU Digital Omnibus proposal and EDPB’s 2026 coordinated enforcement program. Our compliance team works alongside your DPO to ensure every dataset meets both legal and organizational requirements before delivery.rpclegal+1
Hir Infotech serves 30+ industries with specialized data collection expertise, including: e-commerce and retail, financial services and fintech, pharmaceutical and life sciences, real estate and PropTech, travel and hospitality, automotive, industrial manufacturing, logistics and supply chain, HR technology, SaaS and B2B software, media and publishing, energy and utilities, and professional services. Our domain-specific collection pipelines are designed with industry-relevant data schemas, source coverage, and entity taxonomies — rather than generic, one-size-fits-all extraction tools.
For standard use cases (competitive pricing, lead generation, market monitoring), our team can design, test, and deliver a production-ready data collection pipeline within 5–10 business days. Complex multi-source, multi-country, or custom-schema projects typically require 2–4 weeks for full deployment, including compliance review and integration testing. Urgent requirements can be fast-tracked through our priority engagement program. We provide transparent project timelines with milestone-level visibility so your stakeholders always know where the engagement stands.
Yes. Hir Infotech’s technical infrastructure includes full headless browser rendering capabilities for JavaScript-rendered pages, single-page applications, and dynamically loaded content. For publicly accessible but heavily protected pages, our AI-powered anti-bot bypass technology handles proxy rotation, browser fingerprint management, and CAPTCHA resolution with high success rates. We do not collect data from password-protected, authenticated, or private environments — our services are strictly limited to publicly accessible web content, ensuring full legal compliance.
We deliver structured data in your preferred format: JSON, CSV, XML, Excel, Parquet, or via direct database delivery (PostgreSQL, MySQL, MongoDB). For continuous pipelines, we offer REST API delivery, WebSocket streaming, SFTP file transfer, or direct cloud storage delivery to AWS S3, Google Cloud Storage, or Azure Blob Storage. Data schemas are custom-mapped to your internal taxonomy and field naming conventions — pre-formatted for direct ingestion into Salesforce, HubSpot, Snowflake, BigQuery, Redshift, Tableau, or your preferred analytics environment without intermediate transformation.
Hir Infotech maintains a 99.5%+ data accuracy guarantee across all collection pipelines through a three-layer quality assurance process: AI anomaly detection that flags records deviating from expected patterns, automated schema validation that enforces field-level data integrity rules, and human QA review for critical datasets and initial delivery milestones. Every dataset includes a quality summary report detailing extraction success rates, validation pass rates, and any flagged anomalies. If accuracy falls below agreed SLA thresholds, we re-collect and re-deliver at no additional cost.
Absolutely. Integration-ready delivery is a core part of every Hir Infotech engagement. Our technical team works with your data engineers to map extracted fields to your CRM schema (Salesforce, HubSpot, Zoho, Pipedrive, Microsoft Dynamics), data warehouse (Snowflake, BigQuery, Databricks, Redshift), or BI tool (Tableau, Power BI, Looker). We provide API documentation, sample payload schemas, and dedicated integration support to ensure your data flows are operational before the project closes — not after a painful self-service setup.
Website structural changes — updated HTML schemas, new navigation patterns, modified data attributes — are the most common cause of scraping failures with generic tools. Hir Infotech addresses this with self-healing pipeline architecture: AI models continuously monitor extraction success rates per data field, and when a break is detected, automated alerts trigger pipeline inspection within 30 minutes. Our engineering team resolves structural breakages within the same business day under standard SLA, or within 4 hours under our premium monitoring tier — ensuring continuous data delivery with minimal disruption.
Freelancers and generic data marketplaces provide commodity outputs — raw, unvalidated data without compliance documentation, integration support, SLA guarantees, or domain expertise. Hir Infotech delivers a managed intelligence service: dedicated data engineers, AI-powered validation, GDPR/CCPA compliance frameworks, custom schema delivery, direct system integrations, and contractual accuracy guarantees — all backed by 13+ years of enterprise experience and 2,745+ satisfied clients across three continents. For B2B organizations where data quality directly impacts revenue, compliance, and strategic decisions, the difference between a freelancer and Hir Infotech is the difference between a risk and a competitive advantage.
+91 99099 90610
+91 94096 28528
inquiry@hirinfotech.com