
29-January-2026
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...
In 2026, the companies winning market share aren’t just collecting data — they’re crawling smarter. Hir Infotech delivers enterprise-grade AI-driven data crawling solutions trusted by 2,745+ clients across the USA, Europe, and Australia. With 13+ years of deep technical expertise and thousands of projects delivered across 52+ countries, we transform raw, unstructured web data into structured, decision-ready intelligence — at scale, on schedule, and in full compliance. Whether you’re a CTO in California, a CDO in Germany, or a Product Leader in Sydney, Hir Infotech is your trusted data crawling partner.


3,752+
Projects Delivered
2,745+
Happy Clients
2,745+
Happy Clients
99.5%
Data Accuracy
52+
Countries Served
In today's hyper-competitive digital economy, access to real-time, structured external data is no longer a luxury — it is a baseline operational requirement. B2B enterprises across the USA, UK, Germany, France, Netherlands, Sweden, Austria, Switzerland, Spain, Italy, Denmark, Iceland, and Australia rely on systematic data crawling to monitor competitor activity, track price shifts, enrich product catalogs, and surface emerging market trends before rivals do. Manual data collection is simply not scalable: a single enterprise-grade crawling operation can monitor millions of web pages daily, delivering consistent, clean, and structured data directly into your BI dashboards, CRMs, or data lakes. At Hir Infotech, our AI-driven crawling infrastructure handles JavaScript-heavy pages, dynamic content, login-gated sources, and complex pagination — the exact challenges that defeat generic tools and in-house scripts. Serving clients from San Francisco to Stockholm, Frankfurt to Melbourne, our team combines 13+ years of domain expertise with modern machine learning crawlers to deliver data pipelines that are accurate, compliant, and built to last.
Hir Infotech’s AI-powered crawling infrastructure is purpose-built for mid-market and enterprise B2B operations, combining intelligent automation, compliance architecture, and human QA oversight to deliver structured data you can act on immediately.
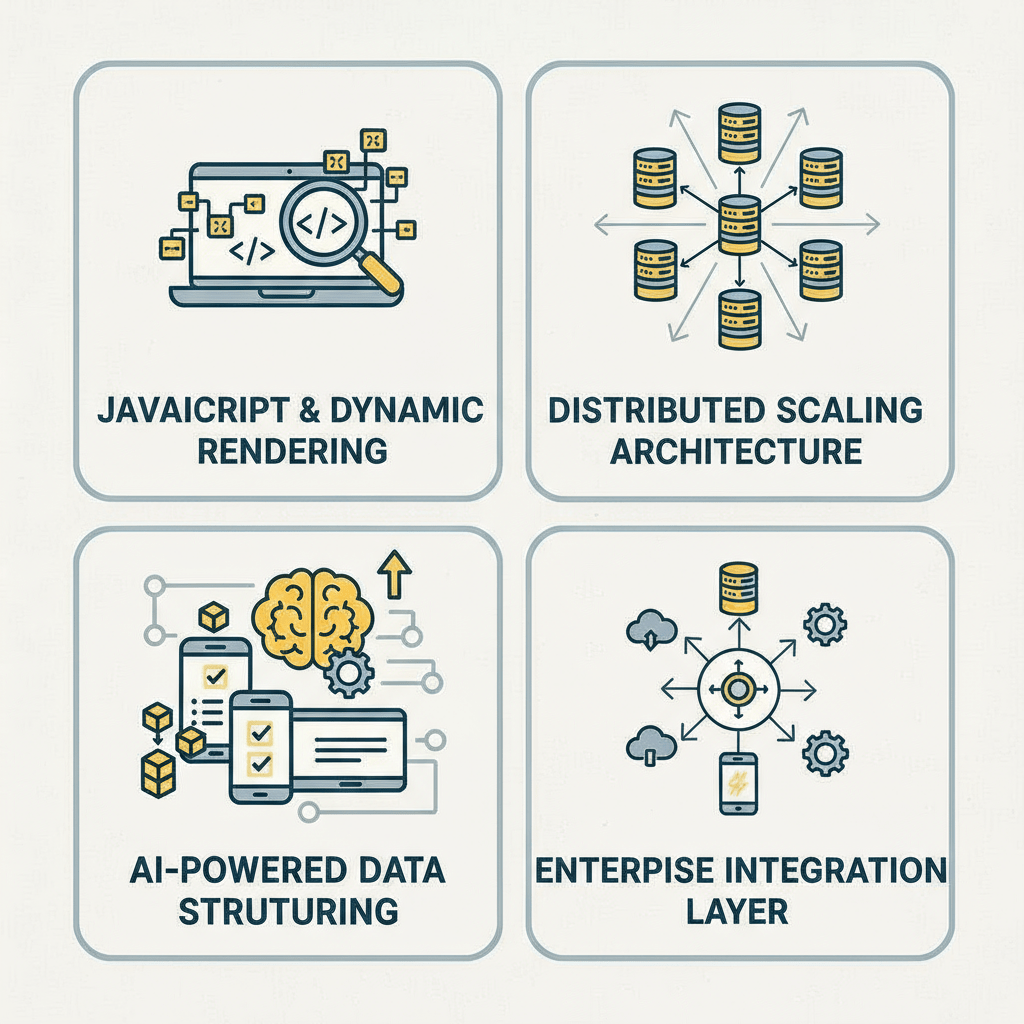
Self-healing crawlers that automatically detect and adapt to website structure changes, DOM updates, and anti-bot mechanisms — ensuring 99.5%+ uptime and data continuity without manual intervention.
Every crawl delivers output in validated, pre-defined schemas — JSON, CSV, XML, or direct database feeds — with built-in data quality checks, deduplication, and field-level validation before delivery.
Enterprise-grade rotating proxy networks with geo-specific IP pools across the USA, EU, UK, and Australia, enabling compliant, anonymous, large-scale data collection from region-locked or geo-sensitive sources.
Fully cloud-hosted crawling infrastructure on AWS and GCP, with elastic scaling to handle 10M+ page crawls per day — no hardware investment, no capacity ceiling, and 24/7 monitoring by our dedicated data engineering team.
















Amazon’s vast product catalogue makes it the world’s most critical crawling target for e-commerce businesses. Crawling Amazon delivers real-time pricing data, competitor ASINs, review sentiment, inventory signals, and Buy Box status — enabling dynamic pricing strategies and catalog enrichment at enterprise scale.
LinkedIn is the definitive B2B data source for companies building targeted prospect lists. Crawling LinkedIn company profiles, job postings, and decision-maker data powers account-based marketing, sales prospecting, and talent intelligence across Europe, the USA, and Australia.
US-based enterprises use Yelp and Google Business crawling to monitor competitor reviews, local service listings, business hours, contact data, and customer sentiment — fueling reputation management and hyperlocal market intelligence programs.
Trustpilot is Europe’s most authoritative consumer review platform. Crawling Trustpilot reviews across Germany, France, UK, Netherlands, and Denmark allows brand teams and product leaders to track sentiment shifts, identify service gaps, and benchmark NPS against competitors in near-real time.
Real estate platforms like Idealista (Spain) and Immobilienscout24 (Germany) contain millions of live property listings. Crawling these platforms delivers rental price trends, property type distributions, geographic demand patterns, and yield analytics critical for PropTech, investment, and financial services firms operating across European markets.
Australia’s leading job board (Seek) and real estate platform (Domain.com.au) are rich data sources for workforce intelligence and property market analytics. Crawling these platforms gives Australian enterprises real-time insights into salary benchmarks, talent availability, property pricing, and suburb-level market trends.
Statistical platforms like Statista and Eurostat publish structured economic, industry, and demographic data critical for market entry, financial modelling, and strategic planning. Crawling these sources aggregates macroeconomic intelligence across Austria, Sweden, Switzerland, Iceland, Italy, and beyond for enterprise strategy teams.
HR and People Analytics teams crawl Indeed and Glassdoor to extract job posting volumes, required skill sets, salary bands, and employer review data — enabling workforce planning, compensation benchmarking, and competitive hiring intelligence across the USA and UK markets.
SaaS-focused enterprises use G2 and Capterra crawling to systematically monitor product reviews, feature requests, competitor ratings, and customer pain points across hundreds of software categories — feeding product roadmap decisions and go-to-market messaging with authentic voice-of-customer data.
As regulatory complexity grows and data volumes explode, enterprise B2B leaders increasingly seek managed data crawling partners rather than building brittle in-house solutions. The average Fortune 500 enterprise today processes millions of external data points daily — from competitive pricing signals to supply chain monitoring, regulatory change tracking, and lead enrichment. Building and maintaining this infrastructure internally demands significant engineering resources and continuous attention to anti-bot countermeasures, compliance updates, and schema maintenance. Hir Infotech eliminates this burden entirely. Our fully managed AI-driven data crawling service handles everything from initial crawler architecture and proxy management to QA validation, schema enforcement, and delivery — so your data team can focus on analysis, not infrastructure. With clients across 52+ countries, including major enterprises in the USA, Germany, UK, France, Netherlands, Sweden, and Australia, we bring tested, proven crawling pipelines that simply work — at scale, on schedule, and within budget.
Why B2B Leaders in the USA, UK, Germany, and Australia Choose Hir Infotech for Data Crawling:
For B2B companies competing across fragmented European markets — from the UK and Germany to Spain, Italy, Denmark, and Iceland — the ability to access real-time, localized web data is a decisive competitive advantage. Traditional data providers offer static, stale datasets that don’t capture the velocity of price changes, competitor product launches, or shifting regulatory content. Hir Infotech’s AI-driven crawling pipelines are engineered for real-time extraction across multi-language, region-locked European websites, using geo-targeted IP pools, language-aware parsers, and country-specific compliance protocols. Our crawlers adapt dynamically to local website structures, currency formats, and content patterns — delivering unified, normalized datasets that power pricing intelligence engines, market entry analysis, compliance monitoring, and lead enrichment programs across all major European markets. With 13+ years of experience serving global clients and an 87% client retention rate, Hir Infotech is the preferred data crawling partner for enterprises that cannot afford data gaps, downtime, or compliance risk.
Long-Tail Services We Deliver Across Europe:
Client Background:
A mid-market US-based multi-category e-commerce retailer with over 200,000 SKUs and operations across 14 US states, competing directly with Amazon, Walmart, and Target in consumer electronics and home goods.
Challenge:
The client’s pricing team was manually tracking competitor prices using browser extensions and spreadsheets — a process that covered fewer than 5% of their SKU base and introduced 48–72 hour pricing lag. They were losing margin on high-velocity products where competitors adjusted prices multiple times daily.
Solution:
Hir Infotech deployed a fully managed AI-driven web crawling pipeline that continuously monitored 32 competitor domains, extracting price, stock availability, promotional tags, and delivery timelines for 210,000+ SKUs at 6-hour intervals. The structured data was delivered directly to the client’s dynamic pricing engine via REST API.
Results:
Within 90 days, the client achieved a 14% improvement in gross margin on high-competition SKUs, reduced pricing lag from 72 hours to under 4 hours, and expanded competitor coverage from 5% to 97% of their active catalog. The crawling infrastructure scaled from 210,000 to 380,000 SKUs within six months with zero engineering effort from the client’s team.
Client Testimonial:
“Hir Infotech’s data crawling service transformed our pricing operation. We went from guessing to knowing — in real time. The ROI was visible within the first quarter.”
— VP of Pricing Strategy, US E-Commerce Retailer
Client Background:
A B2B SaaS company headquartered in London, UK, providing HR workflow automation software to mid-market enterprises across the UK, Germany, and the Netherlands, with an SDR team of 18 targeting 3,000 new accounts per quarter.
Challenge:
The sales team relied on a static CRM database that was 14–18 months out of date. Key contact records were stale — job titles had changed, companies had merged, and decision-makers had moved on. The SDR team reported a 60%+ bounce rate on outbound sequences, wasting budget and eroding sender reputation.
Solution:
Hir Infotech built a continuous crawling and data enrichment pipeline targeting LinkedIn company profiles, company websites, and industry directories across the UK and DACH region. The pipeline delivered weekly-refreshed contact records — including verified job titles, direct emails, company size, funding status, and technology stack signals — directly into the client’s HubSpot CRM.
Results:
Email bounce rates dropped from 62% to under 8% within 60 days. The SDR team’s connect rate increased by 31%, and quarterly pipeline generation grew by 44%. The client expanded the crawling program to cover France and Spain within four months of deployment.
Client Testimonial:
“Our CRM went from a liability to our most valuable sales asset. Hir Infotech’s crawling cadence keeps our data fresh, and the HubSpot integration made it seamless.”
— Head of Revenue Operations, UK SaaS Company
Client Background:
A Berlin-based PropTech startup providing investment analytics and property valuation tools to institutional real estate investors across Germany, Austria, and Switzerland.
Challenge:
The client needed continuous, structured property listing data — rental prices, square footage, location coordinates, energy ratings, and market days — from 12 German property portals including Immobilienscout24, Immonet, and Immowelt. Existing data providers offered weekly batch exports at high cost, with no granularity at the micro-location level.
Solution:
Hir Infotech deployed a daily crawling pipeline across all 12 target portals, extracting 40+ structured data fields per listing, with geo-enrichment (lat/long mapping) and GDPR-compliant processing built in. Data was normalized across portal formats and delivered to the client’s PostgreSQL data warehouse via nightly automated loads.
Results:
The client’s valuation model accuracy improved by 22%, powered by daily price signals versus weekly. Time-to-insight for investment committee reports dropped from 5 days to 4 hours. The startup used this data infrastructure as a key differentiator in securing €4.2M in Series A funding.
Client Testimonial:
“Having daily, structured, compliant property data from across Germany’s fragmented portal landscape gave us an edge no competitor could match. Hir Infotech delivered beyond expectations.”
— Co-Founder & CTO, Berlin PropTech Startup
Client Background:
A Paris-headquartered insurance group offering health, life, and property products to consumers and SMEs across France, Belgium, Italy, and Spain. The strategy team needed continuous competitive intelligence on product pricing, coverage terms, and promotional offers from 28 competitor insurers.
Challenge:
Competitor insurance product pages frequently updated pricing, excess structures, and coverage limits — sometimes weekly. The strategy team’s quarterly manual review process was too slow to inform product positioning or campaign launches, resulting in missed market opportunities and outdated pricing assumptions.
Solution:
Hir Infotech built a multi-language web crawling system capable of parsing French, Italian, and Spanish insurance product pages, extracting structured pricing tables, coverage breakdowns, and promotional callouts on a weekly automated cadence. Custom change-detection logic flagged significant pricing or product changes for immediate alert to the strategy team.
Results:
The client reduced competitive analysis cycle time from 90 days to 7 days, enabling 4x faster product response to market pricing changes. The team identified a 12% pricing gap on health products in the Italian market, leading to a targeted repricing campaign that grew Italian health policy sales by 19% in two quarters.
Client Testimonial:
“The competitive crawling program gave our strategy team a live dashboard of the market. We stopped reacting and started anticipating. Hir Infotech is a true data partner.”
— Chief Strategy Officer, French Insurance Group
Client Background:
A Sydney-based online marketplace connecting Australian consumers with local and international electronics, sporting goods, and homewares brands — with over 85,000 active SKUs from 1,200 supplier partners.
Challenge:
Approximately 34% of product listings lacked complete attribute data — missing dimensions, specifications, material details, or secondary images. Incomplete listings reduced search visibility, increased return rates, and depressed conversion. Manually filling data gaps for 29,000+ products was estimated to take 18 months with the existing team.
Solution:
Hir Infotech designed a crawling and extraction pipeline targeting supplier brand websites, manufacturer PDFs, and wholesale directory portals across Australia and Asia-Pacific. The pipeline extracted, cleaned, and normalized 22 structured product attributes per SKU and delivered enriched data directly into the client’s product database via API.
Results:
Catalog completeness improved from 66% to 97% within 11 weeks. Organic search impressions grew by 28% as richer product data improved Google Shopping and site search relevance. Return rates dropped by 11% due to more accurate product descriptions, and average order value increased by 7%.
Client Testimonial:
“Our catalog went from an incomplete patchwork to a conversion engine. Hir Infotech’s crawling team was fast, thorough, and deeply professional throughout.”
— Head of Marketplace Operations, Sydney E-Commerce Platform
Client Background:
A Chicago-based HR analytics SaaS platform providing workforce planning and talent market intelligence tools to Fortune 500 HR leaders across the USA, UK, and Canada.
Challenge:
The platform’s talent intelligence product required continuous, structured job posting data from 40+ job boards and employer career pages to power salary benchmarking, skills demand tracking, and hiring velocity analytics. Their existing third-party data feed was 3–5 days behind, lacked company-level granularity, and missed emerging skills taxonomy changes in real time.
Solution:
Hir Infotech built a real-time job crawling pipeline covering 40 job boards (including Indeed, LinkedIn Jobs, Glassdoor, ZipRecruiter, and 36 niche sector boards) plus 500 direct employer career pages. Structured outputs included job title, seniority, required skills, compensation range, location, and posting date — delivered via streaming API with under 6-hour data latency.
Results:
Data latency reduced from 72 hours to under 6 hours. Job posting coverage increased by 340%. The client launched a new “Real-Time Skills Demand” product module within six months of deploying the crawling pipeline, contributing to a 27% increase in platform ARR.
Client Testimonial:
“Hir Infotech’s crawling infrastructure became the data foundation of our most successful new product. The speed, coverage, and reliability are genuinely best-in-class.”
— Chief Product Officer, US HR Analytics Platform
Client Background:
An Amsterdam-based RegTech firm delivering automated compliance monitoring tools to financial services clients across the Netherlands, Germany, Denmark, and Sweden, tracking regulatory updates from 120+ European regulatory bodies and government portals.
Challenge:
Regulatory portals across EU member states publish updates in multiple languages, inconsistent formats, and without standardized notification mechanisms. The firm’s compliance analysts were spending 60% of their time manually checking portals for updates rather than interpreting and acting on them — a process that still missed 15–20% of material changes.
Solution:
Hir Infotech deployed a multilingual regulatory crawling system covering 120 EU regulatory portals in Dutch, German, Danish, Swedish, French, and English. The pipeline used change-detection algorithms to identify new publications, amendments, and consultations, extracting structured metadata (date, regulator, topic, jurisdiction) and delivering alerts to the client’s compliance platform within 2 hours of publication.
Results:
Manual monitoring time dropped by 78%. Regulatory update coverage increased from 80% to 99.2%. The firm’s client churn rate fell by 23% as compliance officers reported dramatically improved confidence in the comprehensiveness of their monitoring. The solution was recognized as a finalist at the 2025 European RegTech Awards.
Client Testimonial:
“Hir Infotech solved one of RegTech’s hardest problems — comprehensive, real-time regulatory crawling across 12 jurisdictions and 6 languages. Their team’s expertise is unmatched.”
— CEO, Amsterdam RegTech Firm
Client Background:
A mid-market US-based multi-category e-commerce retailer with over 200,000 SKUs and operations across 14 US states, competing directly with Amazon, Walmart, and Target in consumer electronics and home goods.
Challenge:
The client’s pricing team was manually tracking competitor prices using browser extensions and spreadsheets — a process that covered fewer than 5% of their SKU base and introduced 48–72 hour pricing lag. They were losing margin on high-velocity products where competitors adjusted prices multiple times daily.
Solution:
Hir Infotech deployed a fully managed AI-driven web crawling pipeline that continuously monitored 32 competitor domains, extracting price, stock availability, promotional tags, and delivery timelines for 210,000+ SKUs at 6-hour intervals. The structured data was delivered directly to the client’s dynamic pricing engine via REST API.
Results:
Within 90 days, the client achieved a 14% improvement in gross margin on high-competition SKUs, reduced pricing lag from 72 hours to under 4 hours, and expanded competitor coverage from 5% to 97% of their active catalog. The crawling infrastructure scaled from 210,000 to 380,000 SKUs within six months with zero engineering effort from the client’s team.
Client Testimonial:
“Hir Infotech’s data crawling service transformed our pricing operation. We went from guessing to knowing — in real time. The ROI was visible within the first quarter.”
— VP of Pricing Strategy, US E-Commerce Retailer
Client Background:
A B2B SaaS company headquartered in London, UK, providing HR workflow automation software to mid-market enterprises across the UK, Germany, and the Netherlands, with an SDR team of 18 targeting 3,000 new accounts per quarter.
Challenge:
The sales team relied on a static CRM database that was 14–18 months out of date. Key contact records were stale — job titles had changed, companies had merged, and decision-makers had moved on. The SDR team reported a 60%+ bounce rate on outbound sequences, wasting budget and eroding sender reputation.
Solution:
Hir Infotech built a continuous crawling and data enrichment pipeline targeting LinkedIn company profiles, company websites, and industry directories across the UK and DACH region. The pipeline delivered weekly-refreshed contact records — including verified job titles, direct emails, company size, funding status, and technology stack signals — directly into the client’s HubSpot CRM.
Results:
Email bounce rates dropped from 62% to under 8% within 60 days. The SDR team’s connect rate increased by 31%, and quarterly pipeline generation grew by 44%. The client expanded the crawling program to cover France and Spain within four months of deployment.
Client Testimonial:
“Our CRM went from a liability to our most valuable sales asset. Hir Infotech’s crawling cadence keeps our data fresh, and the HubSpot integration made it seamless.”
— Head of Revenue Operations, UK SaaS Company
Client Background:
A Berlin-based PropTech startup providing investment analytics and property valuation tools to institutional real estate investors across Germany, Austria, and Switzerland.
Challenge:
The client needed continuous, structured property listing data — rental prices, square footage, location coordinates, energy ratings, and market days — from 12 German property portals including Immobilienscout24, Immonet, and Immowelt. Existing data providers offered weekly batch exports at high cost, with no granularity at the micro-location level.
Solution:
Hir Infotech deployed a daily crawling pipeline across all 12 target portals, extracting 40+ structured data fields per listing, with geo-enrichment (lat/long mapping) and GDPR-compliant processing built in. Data was normalized across portal formats and delivered to the client’s PostgreSQL data warehouse via nightly automated loads.
Results:
The client’s valuation model accuracy improved by 22%, powered by daily price signals versus weekly. Time-to-insight for investment committee reports dropped from 5 days to 4 hours. The startup used this data infrastructure as a key differentiator in securing €4.2M in Series A funding.
Client Testimonial:
“Having daily, structured, compliant property data from across Germany’s fragmented portal landscape gave us an edge no competitor could match. Hir Infotech delivered beyond expectations.”
— Co-Founder & CTO, Berlin PropTech Startup
Client Background:
A Paris-headquartered insurance group offering health, life, and property products to consumers and SMEs across France, Belgium, Italy, and Spain. The strategy team needed continuous competitive intelligence on product pricing, coverage terms, and promotional offers from 28 competitor insurers.
Challenge:
Competitor insurance product pages frequently updated pricing, excess structures, and coverage limits — sometimes weekly. The strategy team’s quarterly manual review process was too slow to inform product positioning or campaign launches, resulting in missed market opportunities and outdated pricing assumptions.
Solution:
Hir Infotech built a multi-language web crawling system capable of parsing French, Italian, and Spanish insurance product pages, extracting structured pricing tables, coverage breakdowns, and promotional callouts on a weekly automated cadence. Custom change-detection logic flagged significant pricing or product changes for immediate alert to the strategy team.
Results:
The client reduced competitive analysis cycle time from 90 days to 7 days, enabling 4x faster product response to market pricing changes. The team identified a 12% pricing gap on health products in the Italian market, leading to a targeted repricing campaign that grew Italian health policy sales by 19% in two quarters.
Client Testimonial:
“The competitive crawling program gave our strategy team a live dashboard of the market. We stopped reacting and started anticipating. Hir Infotech is a true data partner.”
— Chief Strategy Officer, French Insurance Group
Client Background:
A Sydney-based online marketplace connecting Australian consumers with local and international electronics, sporting goods, and homewares brands — with over 85,000 active SKUs from 1,200 supplier partners.
Challenge:
Approximately 34% of product listings lacked complete attribute data — missing dimensions, specifications, material details, or secondary images. Incomplete listings reduced search visibility, increased return rates, and depressed conversion. Manually filling data gaps for 29,000+ products was estimated to take 18 months with the existing team.
Solution:
Hir Infotech designed a crawling and extraction pipeline targeting supplier brand websites, manufacturer PDFs, and wholesale directory portals across Australia and Asia-Pacific. The pipeline extracted, cleaned, and normalized 22 structured product attributes per SKU and delivered enriched data directly into the client’s product database via API.
Results:
Catalog completeness improved from 66% to 97% within 11 weeks. Organic search impressions grew by 28% as richer product data improved Google Shopping and site search relevance. Return rates dropped by 11% due to more accurate product descriptions, and average order value increased by 7%.
Client Testimonial:
“Our catalog went from an incomplete patchwork to a conversion engine. Hir Infotech’s crawling team was fast, thorough, and deeply professional throughout.”
— Head of Marketplace Operations, Sydney E-Commerce Platform
Client Background:
A Chicago-based HR analytics SaaS platform providing workforce planning and talent market intelligence tools to Fortune 500 HR leaders across the USA, UK, and Canada.
Challenge:
The platform’s talent intelligence product required continuous, structured job posting data from 40+ job boards and employer career pages to power salary benchmarking, skills demand tracking, and hiring velocity analytics. Their existing third-party data feed was 3–5 days behind, lacked company-level granularity, and missed emerging skills taxonomy changes in real time.
Solution:
Hir Infotech built a real-time job crawling pipeline covering 40 job boards (including Indeed, LinkedIn Jobs, Glassdoor, ZipRecruiter, and 36 niche sector boards) plus 500 direct employer career pages. Structured outputs included job title, seniority, required skills, compensation range, location, and posting date — delivered via streaming API with under 6-hour data latency.
Results:
Data latency reduced from 72 hours to under 6 hours. Job posting coverage increased by 340%. The client launched a new “Real-Time Skills Demand” product module within six months of deploying the crawling pipeline, contributing to a 27% increase in platform ARR.
Client Testimonial:
“Hir Infotech’s crawling infrastructure became the data foundation of our most successful new product. The speed, coverage, and reliability are genuinely best-in-class.”
— Chief Product Officer, US HR Analytics Platform
Client Background:
An Amsterdam-based RegTech firm delivering automated compliance monitoring tools to financial services clients across the Netherlands, Germany, Denmark, and Sweden, tracking regulatory updates from 120+ European regulatory bodies and government portals.
Challenge:
Regulatory portals across EU member states publish updates in multiple languages, inconsistent formats, and without standardized notification mechanisms. The firm’s compliance analysts were spending 60% of their time manually checking portals for updates rather than interpreting and acting on them — a process that still missed 15–20% of material changes.
Solution:
Hir Infotech deployed a multilingual regulatory crawling system covering 120 EU regulatory portals in Dutch, German, Danish, Swedish, French, and English. The pipeline used change-detection algorithms to identify new publications, amendments, and consultations, extracting structured metadata (date, regulator, topic, jurisdiction) and delivering alerts to the client’s compliance platform within 2 hours of publication.
Results:
Manual monitoring time dropped by 78%. Regulatory update coverage increased from 80% to 99.2%. The firm’s client churn rate fell by 23% as compliance officers reported dramatically improved confidence in the comprehensiveness of their monitoring. The solution was recognized as a finalist at the 2025 European RegTech Awards.
Client Testimonial:
“Hir Infotech solved one of RegTech’s hardest problems — comprehensive, real-time regulatory crawling across 12 jurisdictions and 6 languages. Their team’s expertise is unmatched.”
— CEO, Amsterdam RegTech Firm
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
With 12+ years of expertise, Hir Infotech has served 2745+ clients globally. Our proven scraping solutions drive B2B success across the USA, Europe, and Australia.
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...

Gain a powerful edge in the 2026 auto market. Leverage automotive data scraping to master dynamic pricing, analyze competitor strategies,...

Unlock smarter investment decisions using real-time LinkedIn data on company growth, talent, and leadership. Gain a critical competitive edge and...

Gain a competitive edge with a powerful News API. This guide explains how it automates data extraction, providing real-time insights...

Unlock powerful aviation intelligence for your travel business. Our 2026 guide to flight data scraping reveals how to track competitor...

Instantly build a powerful recruitment platform by web scraping job boards for thousands of fresh listings. Attract top talent and...
Hir Infotech has helped 2,745+ B2B clients across the USA, Europe, and Australia transform raw web data into competitive advantage — with 13+ years of proven enterprise delivery, 3,752+ projects completed, and an 87% client retention rate.
Stop making decisions on incomplete, outdated information. Let us build your custom data crawling pipeline — compliant, accurate, and delivery-ready in days, not months.
Try our data crawling service risk-free. Tell us your target sources and data schema — we’ll deliver a structured sample dataset at zero cost so you can see the quality before you commit.
Stay ahead of market shifts with continuously updated competitor pricing, product, and promotion data crawled across hundreds of sources simultaneously — giving your strategy team a live pulse on every market you operate in, from the USA to Germany to Australia.
Crawled data is delivered in your preferred format — JSON, CSV, XML, SQL, or direct API — and is pre-mapped for integration with Salesforce, HubSpot, Snowflake, BigQuery, Tableau, Power BI, and all major CRM, ERP, and BI platforms.
Outsourcing enterprise crawling to Hir Infotech eliminates the average $340,000+ annual cost of maintaining an in-house crawling team (engineers, proxies, infrastructure, compliance review) — delivering higher quality data at a fraction of the cost.
Enterprise-grade crawling infrastructure scales from thousands to hundreds of millions of data points without any hardware investment or internal engineering burden — allowing your business to expand data coverage as fast as your growth demands.
Crawlers run around the clock with built-in self-healing capabilities that automatically adapt to website structure changes, anti-bot updates, and layout modifications — ensuring zero data gaps even when target sites change without warning.
Every crawling engagement is architected to comply with GDPR (EU/UK), CCPA (California), and Australia’s Privacy Act — with documented data lineage, robots.txt adherence, and rate-limit protocols that protect your business from regulatory exposure.
Crawling pipelines support extraction from websites in English, German, French, Spanish, Italian, Dutch, Swedish, Danish, and more — delivering normalized, unified datasets from fragmented, multi-language source landscapes across Europe, USA, and Australia.
AI extraction is validated by human QA engineers on every project, ensuring structured outputs are clean, complete, and schema-compliant — so your data science team receives production-ready data, not raw noise requiring hours of cleaning.
Automated crawling and structured data delivery reduce the time from data need to actionable insight from weeks to hours — accelerating product decisions, market entries, pricing strategies, and sales campaigns without waiting for manual research cycles.
With 13+ years of proven delivery experience, 3,752+ completed projects, and an 87% client retention rate, Hir Infotech brings institutional knowledge, process reliability, and deep vertical expertise that generic data marketplaces and freelancers simply cannot match.
At Hir Infotech, we offer flexible pricing models to power your data-driven success. Choose Subscription-Based Pricing for ongoing scraping needs with predictable costs, Pay-As-You-Go for one-off tasks billed by usage, Project-Based Flat Fees for tailored, end-to-end solutions, or Hourly Pricing for custom development and complex challenges. Whatever your budget or project scope, our expert team delivers cost-effective, high-quality web scraping solutions designed to fit your needs.

A one-time fee is charged for a specific project, regardless of volume or duration, based on scope and complexity.
Billed based on the time spent developing, running, or maintaining the scraper, often used for custom or consulting-heavy projects.

Charged based on actual usage, such as per request, per GB of bandwidth, or per page scraped, with no fixed commitment.
pay a recurring fee (monthly or annually) for access to scraping services, often tiered based on usage limits like the number of requests, pages scraped, or data points extracted.
We begin by collaborating with you to define your data needs—be it for a one-time project, recurring insights, or custom solutions. Whether you opt for Pay-As-You-Go flexibility, a Project-Based Flat Fee, Hourly expertise, or a Subscription plan, we align our approach to your objectives.
Our team identifies the websites and data sources critical to your project. We analyze site structures, assess complexity (e.g., static vs. dynamic content), and plan the most efficient scraping strategy, ensuring compliance with public data access norms.
Using cutting-edge tools and custom-built scrapers, we extract data at scale. We tackle challenges like JavaScript-rendered pages or anti-scraping measures with techniques such as:
Raw data is parsed, cleaned, and structured into formats like CSV, JSON, or Excel. We remove duplicates, correct errors, and validate accuracy to ensure you receive reliable, ready-to-use datasets.
Depending on your pricing model, we deliver results how and when you need them:
We monitor site changes, adapt scrapers as needed, and provide support to keep your data flowing seamlessly. Subscription clients enjoy continuous updates, while Hourly clients benefit from hands-on refinements.
Data crawling is the systematic, automated process of navigating web pages to discover and index content across a website or set of URLs — similar to how search engine bots index the web. Web scraping then extracts specific structured data from those crawled pages. In enterprise practice, both are combined: crawlers discover and visit URLs at scale, while extractors pull structured fields (price, title, contact, review, etc.) from each page. Hir Infotech manages the complete pipeline — crawling, extraction, cleaning, and delivery — as a single managed service.
All Hir Infotech crawling projects targeting European data sources are designed with GDPR compliance as a foundational requirement, not an afterthought. This includes strict robots.txt adherence, crawl-rate throttling to avoid server disruption, collection limited to publicly available non-personal data, documented data lineage for audit purposes, and contractual Data Processing Agreements (DPAs) for all relevant engagements. Clients in Germany, Netherlands, France, Sweden, Denmark, Austria, and other EU markets receive region-specific compliance documentation as standard.
Yes. The majority of modern enterprise-grade websites render content via JavaScript frameworks such as React, Angular, or Vue — making traditional static crawlers ineffective. Hir Infotech’s crawling infrastructure uses headless browser technology (Playwright, Puppeteer) to fully render JavaScript before extraction, ensuring 100% data capture from single-page applications, infinite scroll pages, AJAX-loaded content, and login-gated portals where permissible.
Crawling frequency and delivery speed are fully configurable based on your business requirements — from real-time streaming to hourly, daily, weekly, or event-triggered pipelines. Data is delivered in any format you need: JSON, CSV, XML, XLSX, SQL database push, or direct API feed. For clients integrating with Salesforce, HubSpot, Snowflake, BigQuery, or Tableau, we provide pre-mapped, schema-ready data loads that minimize integration effort on your end.
Hir Infotech delivers data crawling solutions across a broad range of B2B industries including e-commerce and retail, financial services and insurance, real estate and PropTech, healthcare and life sciences, technology and SaaS, HR analytics and recruitment, travel and hospitality, media and publishing, manufacturing and supply chain, and legal and compliance (RegTech). We serve clients across the USA, UK, Germany, France, Netherlands, Sweden, Austria, Switzerland, Spain, Italy, Denmark, Iceland, and Australia.
Enterprise websites increasingly deploy anti-bot measures including CAPTCHA challenges, browser fingerprinting, IP rate limiting, and behavioral detection. Hir Infotech’s crawling infrastructure uses enterprise-grade rotating proxy networks with geo-targeted IP pools, intelligent request throttling, and browser fingerprint randomization to navigate these protections within legal and ethical boundaries — ensuring continuous, uninterrupted data delivery even from heavily protected sources.
Yes. Hir Infotech’s cloud-native crawling architecture on AWS and GCP is built for elastic horizontal scaling. We routinely handle crawling programs covering 5M to 50M+ page requests per day for enterprise clients in e-commerce, real estate, HR analytics, and financial services. There is no fixed capacity ceiling — infrastructure scales automatically with demand, ensuring consistent performance during peak crawl windows without any action required from your team.
Data quality at Hir Infotech is enforced through a multi-layer quality assurance process: schema validation at the point of extraction, automated deduplication, field-level completeness checks, outlier detection for numeric fields (e.g., pricing anomalies), and human QA review on all new projects and major structural changes. We target and consistently deliver 99.5%+ structured data accuracy. Clients receive quality reports with each delivery cycle, and our SLAs include data accuracy guarantees with resolution commitments for any quality issues identified.
For standard crawling projects — e-commerce, directories, job boards, business listings — Hir Infotech typically delivers a working prototype within 5–7 business days and full production deployment within 10–14 business days. Complex projects involving multi-language European portals, login-gated sources, or large-scale crawling programs (50+ domains) are scoped individually, with project timelines agreed upfront. All projects begin with a free sample delivery so you can validate data quality before committing to a full engagement.
Generic data marketplaces sell pre-built, static datasets that age quickly and rarely match your exact schema needs. Freelancers lack the infrastructure, compliance governance, and scalability for enterprise-grade programs. Hir Infotech provides fully managed, custom-built crawling pipelines that are tailored to your specific sources, schemas, delivery formats, and compliance requirements — with a dedicated team, 24/7 monitoring, self-healing automation, and 13+ years of enterprise delivery experience. Our 87% client retention rate and 2,745+ satisfied clients across 52 countries reflect the difference in outcomes.
+91 99099 90610
+91 94096 28528
inquiry@hirinfotech.com