
29-January-2026
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...
For over 13 years, Hir Infotech has delivered enterprise-grade web data extraction services that turn publicly available web data into structured, decision-ready intelligence. From Fortune-style mid-market challengers in New York to scaling SaaS platforms in Munich and retail disruptors in Sydney, our AI-powered extraction pipelines help B2B organizations unlock competitive advantage — faster, more accurately, and at a scale no manual research team can match. Whether you need real-time price intelligence, lead enrichment, market monitoring, or regulatory-aligned data feeds, Hir Infotech is the trusted data partner behind your next strategic move.


15,000+
Projects Delivered
99.5%+
Data Accuracy Rate
2,745+
Happy Clients
13+
Years of Expertise
$1.17B
Market Growth
Every day, billions of publicly available data points — prices, listings, reviews, job postings, company profiles, regulatory filings — are updated across the web. Businesses that can systematically extract, clean, and act on this data move faster, price smarter, and sell better than those relying on stale spreadsheets and manual research. Web data extraction is the automated process of collecting structured information from websites and online sources at scale using intelligent crawlers, parsers, and AI-enrichment layers. For B2B companies in the USA, UK, Germany, France, Netherlands, Sweden, and Australia, this capability has shifted from a competitive advantage to a baseline operational necessity.linkedin+2 At Hir Infotech, our AI-driven web data extraction services are built for mid-market and enterprise teams that require high-volume, high-accuracy data pipelines — not one-off scrapes. We serve CTOs, CDOs, Product Leaders, Growth teams, and Procurement managers who need reliable, compliant, integration-ready data delivered on their schedule. With 13+ years of extraction experience across more than 30 industries and 2,745+ satisfied clients across the USA, Europe, and Australia, we bring both technical depth and domain knowledge to every engagement.
Hir Infotech’s web data extraction capabilities combine machine learning, intelligent automation, and compliance-first architecture to deliver structured data pipelines that enterprise teams can trust and build on.linkedin+1
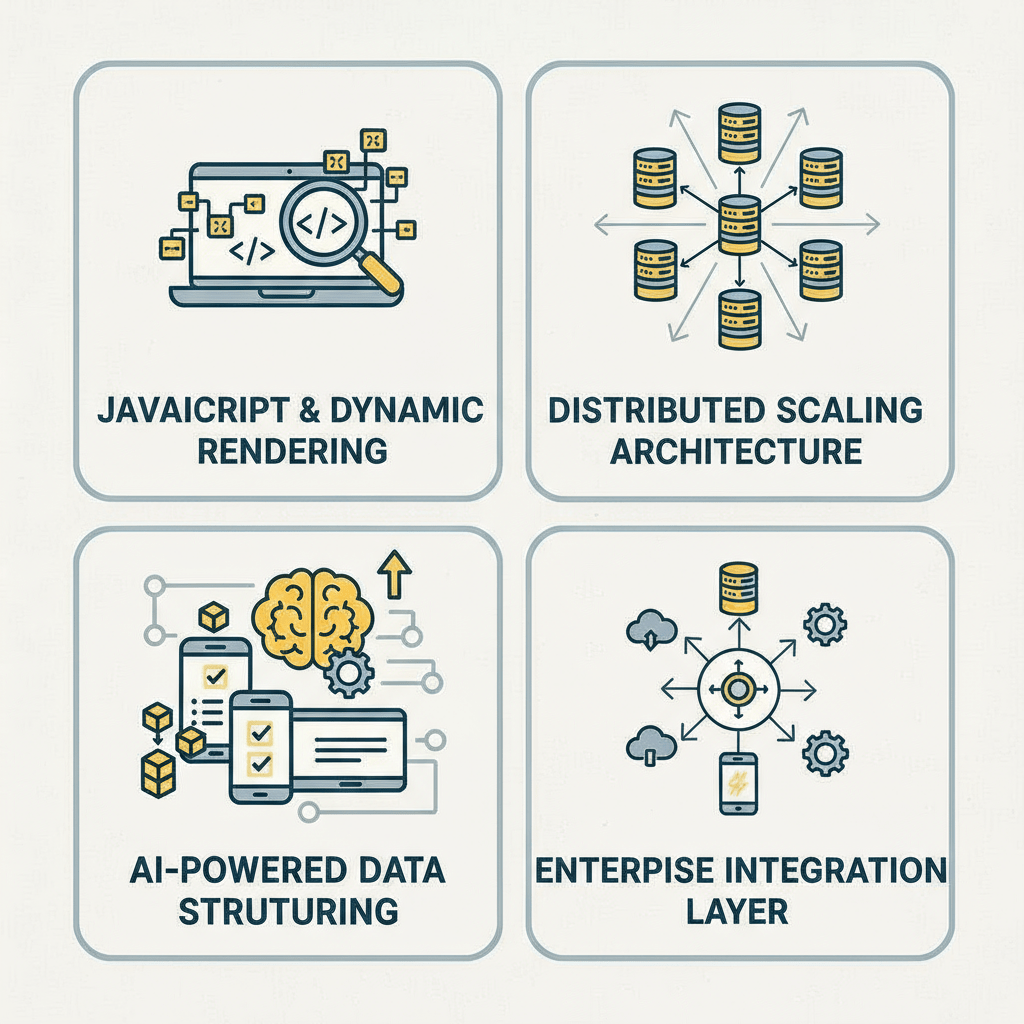
Our extraction layer uses machine learning models trained to interpret dynamic website structures, auto-detect schema changes, and recalibrate selectors without manual intervention — eliminating downtime caused by site redesigns or DOM updates.
Raw scraped content is processed through Natural Language Processing pipelines that classify, normalize, tag, and enrich unstructured text — converting product descriptions, reviews, job posts, and news articles into clean, analytics-ready structured datasets.
We deploy rotating residential proxies, headless browser automation, CAPTCHA resolution, and intelligent rate-throttling to ensure uninterrupted, ethical data collection at scale — without IP blocks or data gaps that compromise your pipeline reliability.
Every extraction workflow is architecturally designed for GDPR, CCPA, and EU AI Act compliance — with data minimization principles, personal data filtering, request logging, and full provenance documentation built in from day one.octoparse+1
















Extract real-time product listings, price points, seller ratings, availability, and promotional data across e-commerce platforms. B2B retailers and brands use this data to power dynamic pricing engines, catalogue management, and competitor benchmarking at scale. According to McKinsey, dynamic pricing powered by real-time competitor data can boost e-commerce revenue by up to 8%.
Scrape firmographic data — company name, size, industry, technology stack, hiring signals, funding rounds — from professional networks and business directories to build high-intent, up-to-date B2B prospect lists. LinkedIn reports that B2B buyers are 5× more likely to engage when outreach is triggered by timely business events.
Collect property listings, price histories, rental yields, agent data, and neighborhood metrics from leading real estate platforms across the USA, UK, and Germany. Real estate investment firms, proptech companies, and mortgage providers use this data to power automated valuation models and portfolio analytics.
Extract structured job postings, salary benchmarks, required skills, hiring volumes, and employer brand signals from job boards across the USA, UK, and Europe. HR tech platforms, workforce analytics firms, and consulting companies use this data to map talent supply, detect hiring intent, and benchmark compensation.
Monitor hotel rates, room availability, guest review scores, and promotional pricing across OTA platforms in real time. Revenue management teams at hotel chains, travel aggregators, and OTAs across Europe and Australia use this data to optimize dynamic pricing and yield management strategies.
Extract financial news articles, press releases, regulatory filings, and sentiment signals from financial media and government portals. Alternative data desks at hedge funds, asset managers, and fintech platforms in the USA, UK, and Switzerland use this to build proprietary market signals and risk models.
Scrape clinical trial listings, drug approval data, physician directories, and healthcare provider profiles from regulatory and industry databases. Pharmaceutical companies, healthcare analytics firms, and medical device companies use this data to accelerate research, improve market access strategies, and map competitive landscapes.
Extract business profiles, contact information, ratings, categories, and geographic data from business directories across the USA, UK, Europe, and Australia. Marketing agencies, CRM platforms, and lead generation companies use this data to build verified, geo-targeted B2B and B2C contact databases.
Collect structured company filings, financial statements, director profiles, and compliance records from government databases across multiple jurisdictions. Legal firms, compliance teams, and due-diligence platforms use this data to power KYC pipelines, M&A screening, and regulatory intelligence workflows.
Manual data collection is no longer viable at enterprise scale. Research analysts spending hours copying competitor prices, building prospect lists from outdated databases, or aggregating market intelligence from dozens of portals introduce latency, error, and cost that directly impair business outcomes. AI-powered web data extraction eliminates these bottlenecks by deploying intelligent, self-maintaining pipelines that collect, clean, and deliver structured data continuously — without human supervision. At Hir Infotech, our enterprise clients across the USA, Germany, Netherlands, Sweden, and Australia have replaced weeks of manual research cycles with automated data feeds that update hourly. With 13+ years of delivery experience and 2,745+ satisfied clients, we understand that data reliability is not just a technical requirement — it is a business-critical dependency. Our pipelines are tested for accuracy, monitored for drift, and backed by SLA commitments that procurement and operations teams can rely on.browserless+1
For businesses operating in the EU — Germany, France, Italy, Spain, Denmark, Netherlands, Iceland, Austria, Sweden, Switzerland — web data extraction must align with GDPR, the EU AI Act (enforceable August 2026), and national-level data regulations. Non-compliance now carries cumulative EU fines exceeding €5.88 billion since 2018, with 2025 alone accounting for €2.3 billion — a 38% year-over-year increase. Hir Infotech’s compliance-first architecture addresses this directly: every extraction project undergoes a data classification review, applies data minimization principles, filters out personally identifiable information at the collection layer, and generates full request logs for auditability. Our legal team and technical architects have deep familiarity with GDPR’s lawful basis requirements for web scraping, CCPA obligations for US-based data subjects, and the emerging requirements of the EU AI Act for organizations deploying AI systems trained on scraped data. Whether you’re a Swiss fintech, a French retail group, or a US SaaS company with European customers, Hir Infotech builds your extraction infrastructure to be compliant by design — not compliant by afterthought.illusory+1
Client Background: A mid-market US-based home goods retailer operating across 14 e-commerce channels with annual revenues of $85M, competing with Amazon third-party sellers and direct-to-consumer brands.
Challenge: The client’s pricing team was manually checking competitor prices twice weekly using spreadsheet trackers. With over 12,000 SKUs and 200+ competing sellers, their pricing was perpetually 36–72 hours behind market movements — resulting in lost cart conversions and margin erosion during promotional periods.
Solution: Hir Infotech deployed a custom AI-powered web data extraction pipeline targeting Amazon, Walmart Marketplace, Wayfair, and 8 niche DTC competitors. The system used adaptive AI selectors to track 12,000 SKUs across all platforms, updating every 4 hours. Extracted price data was normalized and delivered via API directly into the client’s repricing engine and BI dashboard. Anti-block infrastructure ensured 99.7% uptime across all target sites.
Results:
Client Testimonial: “Hir Infotech’s extraction pipeline didn’t just save us time — it fundamentally changed how we compete on price. We’re no longer reacting; we’re anticipating.” — VP of E-Commerce, Home Goods Retailer, Texas, USA
Client Background: A Munich-based B2B SaaS company providing supply chain management software to mid-market manufacturers across the DACH region. Their sales team of 18 account executives relied on a legacy CRM with contacts last validated 18 months prior.
Challenge: Stale CRM data was generating bounce rates of 34% in email campaigns and wasting AE time on outreach to companies that had been acquired, rebranded, or scaled beyond their ICP. The sales ops team needed a scalable way to refresh and enrich 45,000 company records with current firmographic signals.
Solution: Hir Infotech designed a GDPR-compliant data extraction and enrichment pipeline targeting Kompass, Xing, German Trade Register (Bundesanzeiger), LinkedIn company pages, and industry association directories. The pipeline extracted company size, revenue signals, technology stack indicators, recent hiring activity, and key decision-maker titles — all filtered to remove personally identifiable information in accordance with GDPR Article 6 legitimate interest requirements.
Results:
Client Testimonial: “We were skeptical about any data vendor claiming GDPR compliance, but Hir Infotech’s documentation and architecture genuinely satisfied our DPO. The data quality was exceptional.” — Head of Sales Operations, SaaS Company, Munich, Germany
Client Background: A Sydney-based proptech startup providing automated property valuation models (AVMs) to mortgage brokers, banks, and individual investors across New South Wales and Victoria.
Challenge: Their AVM models required continuous feeds of property listing data — sale prices, rental yields, days on market, suburb-level supply/demand signals — from Domain.com.au, realestate.com.au, and local council databases. Manual data collection had made their models 2–3 weeks stale, undermining valuation accuracy and lender confidence.
Solution: Hir Infotech built a scheduled extraction pipeline targeting Australia’s leading real estate portals, delivering normalized, deduplicated property data in JSON format to the client’s AWS data lake twice daily. The pipeline handled pagination, JavaScript rendering, and dynamic search filters to ensure complete suburb-level coverage across both states.
Results:
Client Testimonial: “The extraction pipeline Hir Infotech delivered is now the foundation of our entire product. It’s reliable, accurate, and their team responded within hours whenever we needed adjustments.” — CTO, Proptech Startup, Sydney, Australia
Client Background: A London-headquartered multi-brand retail group with 340 physical stores and a growing online presence across the UK and Ireland, competing in the fashion and home categories.
Challenge: The group’s category managers needed systematic intelligence on competitor pricing, promotional calendars, and product range changes across ASOS, Next, M&S, and 12 regional e-tailers. Their existing approach relied on ad hoc analyst reviews that were subjective, inconsistent, and unable to scale across 80,000+ SKUs.
Solution: Hir Infotech deployed a multi-target web data extraction system covering 16 competitor and marketplace sites. Using NLP-powered data enrichment, extracted product descriptions were auto-categorized and matched to the client’s internal product taxonomy, enabling like-for-like price comparison across product classes. Promotional event detection was added to flag competitor sale events within 2 hours of launch.
Results:
Client Testimonial: “Hir Infotech gave us the data infrastructure we needed to stop guessing and start competing with data. The ROI was evident within the first quarter.” — Chief Commercial Officer, Retail Group, London, UK
Client Background: A quantitative investment manager based in New York with $2.1B AUM, deploying systematic long/short equity strategies across US and European equities.
Challenge: The fund’s research team needed structured alternative data signals — earnings call sentiment, SEC filing velocity, management commentary trends, and news flow — to supplement traditional financial data. Existing commercial data vendors were too slow (weekly feeds) and too expensive ($400K+/year) for the signals they needed.
Solution: Hir Infotech engineered a custom financial data extraction pipeline collecting from SEC EDGAR, regulatory news wires, financial press portals, and company investor relations pages. NLP enrichment classified extracted text for sentiment polarity, topic classification (M&A, guidance, legal risk), and entity recognition. Data was delivered via REST API in near-real-time with full provenance logging.
Results:
Client Testimonial: “This was exactly the kind of flexible, cost-effective data infrastructure we couldn’t find from traditional vendors. Hir Infotech understands what quant teams actually need.” — Head of Data Science, Quantitative Fund, New York, USA
Client Background: A Paris-based MedTech company launching a SaaS platform for medical device distribution across France, Belgium, and Spain, requiring an accurate, up-to-date database of hospitals, clinics, and procurement decision-makers.
Challenge: Existing commercial healthcare databases were 18–24 months stale and poorly structured for French and Belgian provider hierarchies. The company’s sales team of 22 needed targeted, role-level contacts with verified specialties, purchase authority signals, and facility size data.
Solution: Hir Infotech built a targeted extraction pipeline covering the French national healthcare provider registry (Répertoire RPPS), Belgian NIHDI databases, Spanish SNS directories, and procurement-relevant LinkedIn company pages. All extraction was designed to collect only publicly declared institutional data, with personal contact details excluded to ensure GDPR compliance.blog.datahut+1
Results:
Client Testimonial: “Hir Infotech understood the complexity of European healthcare data and delivered something our competitors simply couldn’t — accurate, compliant, actionable provider intelligence.” — CEO, MedTech SaaS Platform, Paris, France
Client Background: A Stockholm-based Online Travel Agency (OTA) serving the Nordic market (Sweden, Denmark, Norway, Finland) with hotel, flight, and car rental booking across 35,000+ travel products.
Challenge: The revenue team needed real-time rate parity monitoring across Booking.com, Expedia, Hotels.com, and 8 supplier direct sites to enforce rate parity agreements and respond to rate violations before they triggered customer complaints or SLA penalties.
Solution: Hir Infotech deployed a real-time web data extraction and monitoring system checking 35,000 travel products across 10 platforms every 3 hours. Automated alerting was integrated into the client’s Slack and CRM workflows to notify revenue managers within 15 minutes of a rate disparity exceeding a configurable threshold.
Results:
Client Testimonial: “We went from discovering rate violations days after the fact to being notified in minutes. That kind of operational edge is invaluable in travel.” — VP Revenue Management, OTA, Stockholm, Sweden
Client Background: A mid-market US-based home goods retailer operating across 14 e-commerce channels with annual revenues of $85M, competing with Amazon third-party sellers and direct-to-consumer brands.
Challenge: The client’s pricing team was manually checking competitor prices twice weekly using spreadsheet trackers. With over 12,000 SKUs and 200+ competing sellers, their pricing was perpetually 36–72 hours behind market movements — resulting in lost cart conversions and margin erosion during promotional periods.
Solution: Hir Infotech deployed a custom AI-powered web data extraction pipeline targeting Amazon, Walmart Marketplace, Wayfair, and 8 niche DTC competitors. The system used adaptive AI selectors to track 12,000 SKUs across all platforms, updating every 4 hours. Extracted price data was normalized and delivered via API directly into the client’s repricing engine and BI dashboard. Anti-block infrastructure ensured 99.7% uptime across all target sites.
Results:
Client Testimonial: “Hir Infotech’s extraction pipeline didn’t just save us time — it fundamentally changed how we compete on price. We’re no longer reacting; we’re anticipating.” — VP of E-Commerce, Home Goods Retailer, Texas, USA
Client Background: A Munich-based B2B SaaS company providing supply chain management software to mid-market manufacturers across the DACH region. Their sales team of 18 account executives relied on a legacy CRM with contacts last validated 18 months prior.
Challenge: Stale CRM data was generating bounce rates of 34% in email campaigns and wasting AE time on outreach to companies that had been acquired, rebranded, or scaled beyond their ICP. The sales ops team needed a scalable way to refresh and enrich 45,000 company records with current firmographic signals.
Solution: Hir Infotech designed a GDPR-compliant data extraction and enrichment pipeline targeting Kompass, Xing, German Trade Register (Bundesanzeiger), LinkedIn company pages, and industry association directories. The pipeline extracted company size, revenue signals, technology stack indicators, recent hiring activity, and key decision-maker titles — all filtered to remove personally identifiable information in accordance with GDPR Article 6 legitimate interest requirements.
Results:
Client Testimonial: “We were skeptical about any data vendor claiming GDPR compliance, but Hir Infotech’s documentation and architecture genuinely satisfied our DPO. The data quality was exceptional.” — Head of Sales Operations, SaaS Company, Munich, Germany
Client Background: A Sydney-based proptech startup providing automated property valuation models (AVMs) to mortgage brokers, banks, and individual investors across New South Wales and Victoria.
Challenge: Their AVM models required continuous feeds of property listing data — sale prices, rental yields, days on market, suburb-level supply/demand signals — from Domain.com.au, realestate.com.au, and local council databases. Manual data collection had made their models 2–3 weeks stale, undermining valuation accuracy and lender confidence.
Solution: Hir Infotech built a scheduled extraction pipeline targeting Australia’s leading real estate portals, delivering normalized, deduplicated property data in JSON format to the client’s AWS data lake twice daily. The pipeline handled pagination, JavaScript rendering, and dynamic search filters to ensure complete suburb-level coverage across both states.
Results:
Client Testimonial: “The extraction pipeline Hir Infotech delivered is now the foundation of our entire product. It’s reliable, accurate, and their team responded within hours whenever we needed adjustments.” — CTO, Proptech Startup, Sydney, Australia
Client Background: A London-headquartered multi-brand retail group with 340 physical stores and a growing online presence across the UK and Ireland, competing in the fashion and home categories.
Challenge: The group’s category managers needed systematic intelligence on competitor pricing, promotional calendars, and product range changes across ASOS, Next, M&S, and 12 regional e-tailers. Their existing approach relied on ad hoc analyst reviews that were subjective, inconsistent, and unable to scale across 80,000+ SKUs.
Solution: Hir Infotech deployed a multi-target web data extraction system covering 16 competitor and marketplace sites. Using NLP-powered data enrichment, extracted product descriptions were auto-categorized and matched to the client’s internal product taxonomy, enabling like-for-like price comparison across product classes. Promotional event detection was added to flag competitor sale events within 2 hours of launch.
Results:
Client Testimonial: “Hir Infotech gave us the data infrastructure we needed to stop guessing and start competing with data. The ROI was evident within the first quarter.” — Chief Commercial Officer, Retail Group, London, UK
Client Background: A quantitative investment manager based in New York with $2.1B AUM, deploying systematic long/short equity strategies across US and European equities.
Challenge: The fund’s research team needed structured alternative data signals — earnings call sentiment, SEC filing velocity, management commentary trends, and news flow — to supplement traditional financial data. Existing commercial data vendors were too slow (weekly feeds) and too expensive ($400K+/year) for the signals they needed.
Solution: Hir Infotech engineered a custom financial data extraction pipeline collecting from SEC EDGAR, regulatory news wires, financial press portals, and company investor relations pages. NLP enrichment classified extracted text for sentiment polarity, topic classification (M&A, guidance, legal risk), and entity recognition. Data was delivered via REST API in near-real-time with full provenance logging.
Results:
Client Testimonial: “This was exactly the kind of flexible, cost-effective data infrastructure we couldn’t find from traditional vendors. Hir Infotech understands what quant teams actually need.” — Head of Data Science, Quantitative Fund, New York, USA
Client Background: A Paris-based MedTech company launching a SaaS platform for medical device distribution across France, Belgium, and Spain, requiring an accurate, up-to-date database of hospitals, clinics, and procurement decision-makers.
Challenge: Existing commercial healthcare databases were 18–24 months stale and poorly structured for French and Belgian provider hierarchies. The company’s sales team of 22 needed targeted, role-level contacts with verified specialties, purchase authority signals, and facility size data.
Solution: Hir Infotech built a targeted extraction pipeline covering the French national healthcare provider registry (Répertoire RPPS), Belgian NIHDI databases, Spanish SNS directories, and procurement-relevant LinkedIn company pages. All extraction was designed to collect only publicly declared institutional data, with personal contact details excluded to ensure GDPR compliance.blog.datahut+1
Results:
Client Testimonial: “Hir Infotech understood the complexity of European healthcare data and delivered something our competitors simply couldn’t — accurate, compliant, actionable provider intelligence.” — CEO, MedTech SaaS Platform, Paris, France
Client Background: A Paris-based MedTech company launching a SaaS platform for medical device distribution across France, Belgium, and Spain, requiring an accurate, up-to-date database of hospitals, clinics, and procurement decision-makers.
Challenge: Existing commercial healthcare databases were 18–24 months stale and poorly structured for French and Belgian provider hierarchies. The company’s sales team of 22 needed targeted, role-level contacts with verified specialties, purchase authority signals, and facility size data.
Solution: Hir Infotech built a targeted extraction pipeline covering the French national healthcare provider registry (Répertoire RPPS), Belgian NIHDI databases, Spanish SNS directories, and procurement-relevant LinkedIn company pages. All extraction was designed to collect only publicly declared institutional data, with personal contact details excluded to ensure GDPR compliance.blog.datahut+1
Results:
Client Testimonial: “Hir Infotech understood the complexity of European healthcare data and delivered something our competitors simply couldn’t — accurate, compliant, actionable provider intelligence.” — CEO, MedTech SaaS Platform, Paris, France
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
With 12+ years of expertise, Hir Infotech has served 2745+ clients globally. Our proven scraping solutions drive B2B success across the USA, Europe, and Australia.
Rely on Hir Infotech for 95%+ accurate data, meticulously verified to fuel your B2B success. Our global scraping solutions deliver trusted insights for confident decision-making worldwide.
Unlock crucial business data by mastering website anti-scraping. Our 2026 guide covers proven strategies from IP rotation to headless browsers...

Gain a powerful edge in the 2026 auto market. Leverage automotive data scraping to master dynamic pricing, analyze competitor strategies,...

Unlock smarter investment decisions using real-time LinkedIn data on company growth, talent, and leadership. Gain a critical competitive edge and...

Gain a competitive edge with a powerful News API. This guide explains how it automates data extraction, providing real-time insights...

Unlock powerful aviation intelligence for your travel business. Our 2026 guide to flight data scraping reveals how to track competitor...

Instantly build a powerful recruitment platform by web scraping job boards for thousands of fresh listings. Attract top talent and...
Hir Infotech has spent 13+ years building the extraction pipelines, compliance frameworks, and AI-enrichment layers that enterprise B2B teams across the USA, Europe, and Australia rely on every day. With 2,745+ satisfied clients and 15,000+ projects delivered, we know what scalable, accurate, and compliant web data extraction looks like in practice — not just in theory.
Request a free sample dataset from your target source. No commitment. Just clean, structured data so you can see the quality before you commit.
Monitor competitor pricing, product launches, promotions, and positioning changes in near-real-time — enabling your commercial and product teams to react within hours rather than weeks, protecting margins and accelerating go-to-market speed.
Our extraction infrastructure covers websites and data sources across the USA, UK, Germany, France, Italy, Spain, Denmark, Netherlands, Iceland, Austria, Sweden, Switzerland, Australia, and beyond — giving global enterprises a single, reliable data partner for all their markets.
From JavaScript-rendered SPAs and login-gated portals to PDFs, APIs, and structured government databases — our engineers architect solutions for sources that generic scraping tools cannot handle, ensuring you get data competitors cannot easily replicate.
Replace 10–50 FTE-hours per week of manual data collection with automated extraction pipelines that scale instantly across thousands of sources, millions of records, and dozens of geographies — without adding headcount or infrastructure.
Structured data is delivered via REST API, CSV/JSON exports, direct database connections, or cloud storage (AWS S3, Google Cloud Storage, Azure Blob) — integrating cleanly into your existing BI tools, CRM platforms, data lakes, or analytics environments.
Every extraction pipeline is architected for data minimization, PII filtering, provenance logging, and lawful basis documentation — protecting your organization from fines that now exceed €5.88 billion cumulatively in the EU alone.
We don’t just scrape — we enrich. NLP classification, entity recognition, sentiment tagging, deduplication, and data normalization are applied at the extraction layer, so your data analysts receive decision-ready datasets rather than raw HTML dumps.
AI-enriched extraction pipelines deliver firmographic data that is current, verified, and matched to your ICP — reducing CRM decay, improving email deliverability, and increasing sales-qualified lead volumes by up to 67% (as evidenced in our DACH case study).
Our adaptive AI selectors automatically detect and respond to site structure changes — maintaining pipeline integrity without manual engineering intervention. SLA-backed uptime commitments ensure your data feeds never silently fail.
Web data extraction delivers quantifiable impact across pricing (+4–8% margin uplift), sales (3× lead conversion improvements), operations (40–85% time savings), and strategy — making it one of the highest-ROI data investments for mid-market and enterprise B2B teams.
At Hir Infotech, we offer flexible pricing models to power your data-driven success. Choose Subscription-Based Pricing for ongoing scraping needs with predictable costs, Pay-As-You-Go for one-off tasks billed by usage, Project-Based Flat Fees for tailored, end-to-end solutions, or Hourly Pricing for custom development and complex challenges. Whatever your budget or project scope, our expert team delivers cost-effective, high-quality web scraping solutions designed to fit your needs.

A one-time fee is charged for a specific project, regardless of volume or duration, based on scope and complexity.
Billed based on the time spent developing, running, or maintaining the scraper, often used for custom or consulting-heavy projects.

Charged based on actual usage, such as per request, per GB of bandwidth, or per page scraped, with no fixed commitment.
pay a recurring fee (monthly or annually) for access to scraping services, often tiered based on usage limits like the number of requests, pages scraped, or data points extracted.
We begin by collaborating with you to define your data needs—be it for a one-time project, recurring insights, or custom solutions. Whether you opt for Pay-As-You-Go flexibility, a Project-Based Flat Fee, Hourly expertise, or a Subscription plan, we align our approach to your objectives.
Our team identifies the websites and data sources critical to your project. We analyze site structures, assess complexity (e.g., static vs. dynamic content), and plan the most efficient scraping strategy, ensuring compliance with public data access norms.
Using cutting-edge tools and custom-built scrapers, we extract data at scale. We tackle challenges like JavaScript-rendered pages or anti-scraping measures with techniques such as:
Raw data is parsed, cleaned, and structured into formats like CSV, JSON, or Excel. We remove duplicates, correct errors, and validate accuracy to ensure you receive reliable, ready-to-use datasets.
Depending on your pricing model, we deliver results how and when you need them:
We monitor site changes, adapt scrapers as needed, and provide support to keep your data flowing seamlessly. Subscription clients enjoy continuous updates, while Hourly clients benefit from hands-on refinements.
Web data extraction is the systematic process of collecting structured information from websites and online sources using automated tools, AI-powered crawlers, and data parsing pipelines. It is often used interchangeably with web scraping, though extraction typically implies a more complete workflow — including data cleaning, normalization, enrichment, and delivery in structured formats ready for business use. At Hir Infotech, our extraction services encompass the full pipeline from source identification and crawling through to clean, analytics-ready data delivery via API or file export — not just raw HTML collection.
Web data extraction of publicly available, non-personally-identifying data is widely accepted as lawful across the USA and Europe for legitimate commercial purposes including competitive intelligence, market research, and lead generation. In the USA, the 2022 hiQ v. LinkedIn ruling reinforced the legality of scraping public data. In the EU, organizations must comply with GDPR — specifically ensuring a lawful basis (typically legitimate interest) for any data collected about identifiable individuals. Hir Infotech builds every project with legal defensibility as a design requirement, including PII filtering, data minimization, and compliance documentation.
Our GDPR compliance framework covers four layers: (1) Data classification — distinguishing personal from non-personal data at the schema design stage; (2) Collection controls — PII filtering and data minimization applied in the extraction pipeline; (3) Provenance logging — full request-level logs maintained for auditability; and (4) Legal basis documentation — written records of the legitimate interest assessment for each project. We also stay current with EU AI Act obligations effective August 2026, which add downstream data governance requirements for AI systems trained on extracted data.blog.
We serve 30+ industries including e-commerce and retail, financial services and fintech, real estate and proptech, healthcare and pharmaceuticals, travel and hospitality, B2B SaaS, recruitment and HR tech, automotive, logistics, and legal/compliance. Our extraction expertise spans USA, UK, Germany, France, Italy, Spain, Denmark, Netherlands, Austria, Sweden, Switzerland, and Australia — with industry-specific experience in each region’s most critical data sources.techbehemoths+1
For standard extraction projects (single-source, structured data, no authentication), our typical setup time is 3–5 business days from scoping to first data delivery. For complex, multi-source, multi-locale enterprise pipelines with enrichment and API delivery, timelines are typically 2–4 weeks depending on source complexity and compliance requirements. We offer a free sample dataset during scoping so you can validate data quality before committing to a full pipeline.
We deliver structured data in JSON, CSV, XML, XLSX, and Parquet formats. Delivery options include REST API (real-time or scheduled), SFTP, cloud storage (AWS S3, Google Cloud Storage, Azure Blob Storage), direct database integration (PostgreSQL, MySQL, BigQuery, Snowflake, Redshift), and webhook-based event triggers. We work with your existing data engineering team to match delivery to your current stack architecture.
Yes. Our extraction infrastructure includes headless browser automation (using Playwright and Puppeteer), session management for login-gated sources (where permitted), rotating residential proxy networks, CAPTCHA resolution layers, and AI-adaptive selectors that handle dynamic DOM structures. This allows us to reliably extract data from sources where generic scraping tools fail — including single-page applications, infinite scroll interfaces, and heavily bot-protected platforms.
Hir Infotech offers flexible pricing models tailored to B2B clients: (1) Project-based pricing for one-time extraction or dataset delivery; (2) Monthly retainer pricing for ongoing scheduled pipelines; (3) Volume-based pricing for large-scale, multi-source enterprise contracts. All engagements begin with a free scoping consultation and sample dataset so you can evaluate quality and fit before committing. Contact our team for a custom quote based on your sources, volume, frequency, and delivery requirements.
Our pipelines are built with multi-layer quality assurance: AI-based validation at extraction, deduplication and schema enforcement during transformation, and human QA review on initial dataset delivery. Our target and typical delivered accuracy for structured data is 99.5%+, with ongoing monitoring to detect and correct drift caused by source changes. We provide data quality reports with each delivery for enterprise clients.
Web data extraction delivers ROI across multiple business functions simultaneously. Sales teams see up to 3× improvements in lead conversion using enriched, intent-based prospect data. Pricing teams achieve 4–8% margin uplift through real-time competitive intelligence. Operations teams reduce manual research hours by 40–85%. Compliance and risk teams reduce exposure through systematic market monitoring. For a mid-market company spending $50K annually on a managed extraction pipeline, typical documented ROI exceeds 300–500% within 12 months — making it one of the most cost-efficient data investments available.
+91 99099 90610
+91 94096 28528
inquiry@hirinfotech.com